Acceleration Is Not All You Need: The State of AI Hardware
By: Jonathan Bown
Date: 07-16-2023
Table of Contents
- Transforming the AI Landscape
- The Deep Learning Hardware Revolution: An Overview
- Measuring AI Hardware Progress
- MLPerf: A Comprehensive Benchmarking Tool
- A Journey Through AI Hardware Advancements
- Greater Pace: Prospects and Challenges
- What the Community Has Learned
- References
- Acknowledgements
Transforming the AI Landscape
Since early 2021, there has been an unprecedented transformation in artificial intelligence (AI) system hardware capabilities, surpassing traditional benchmarks such as Moore’s Law, which predicts a two-year doubling rate of transistors on a circuit. Processing capability has historically been limited by the number of transistors; however, recent years have witnessed an accelerated doubling rate of processing power, particularly in hardware designed for AI applications. The current doubling rates are outpacing not only technological growth as predicted by Moore’s Law, but also biological evolution, which has taken millions of years. This has occurred despite an overall deceleration in the doubling rate of transistors. Epic Games CEO Tim Sweeney recently noted this phenomenon, “Artificial intelligence is doubling at a rate much faster than Moore’s Law’s 2 years, or evolutionary biology’s 2M years. Why? Because we’re bootstrapping it on the back of both laws. And if it can feed back into its own acceleration, that’s a stacked exponential” (Sweeney, 2023).
This raises the question: How has such rapid innovation in AI systems been enabled despite a slowdown in traditional hardware performance standards? The rapid acceleration of AI related hardware capabilities has profound implications for the practitioners within the machine learning (ML) community and the long-term outlook for our ability to provide value. This essay will explore the key breakthroughs, driving forces, and alternate performance measures of processing hardware developed during the period of 2021 to mid-2023. The discussion will focus on how processing and acceleration advancements impact various data types, improve the efficiency of AI applications, and make complex AI systems more accessible. While it is impossible to detail every development, this essay strives to provide a comprehensive picture of how working and experimenting with AI hardware within this recent timeframe has changed the ML community.
The Deep Learning Hardware Revolution: An Overview
Coined in 1956 by scientists including John McCarthy and Marvin Minsky, “artificial intelligence” ignited an investment wave that led to an “AI bubble” during the 1970s. However, the computational demands of early AI quickly outpaced CPU capabilities. CPUs are capable of performing a variety of complex tasks, but they do so sequentially. This meant that they were not well-suited to the vector and matrix operations that AI algorithms require. When the “AI Bubble” burst in the early 1980s, AI development regressed into what is now referred to as the “AI winter” (Jotrin Electronics, 2022)
In 1999, Nvidia introduced the Graphics Processing Unit (GPU), a new type of processor that enabled many operations to be performed simultaneously. This speedup in computation capability earned GPUs the name “accelerators.” GPUs are much better suited to manage the vector and matrix operations that AI algorithms require.
The true potential of GPUs for AI was first recognized in 2012 when a neural network model known as AlexNet, trained using Nvidia’s GPUs, won the ImageNet competition. This achievement sparked widespread acceptance of GPUs for AI (Amodei & Hernandez, 2018). Since then, specialized hardware accelerators meant for large amounts of mathematical computations such as Tensor Processing Units (TPUs), Neural Processing Units (NPUs), and Intelligence Processing Units (IPUs) have become essential tools for AI model training and deployment. Further innovations in the field, including AI-assisted chip design, started gaining popularity around 2018. These led to the development of frameworks like Google’s chip design optimization platform (Goldie & Mirhoseini, 2020) and Synopsys’ DSO.ai, an AI application for autonomous chip design (Synopsys, 2023).
The ongoing global chip shortage, triggered by the COVID-19 pandemic, has highlighted the need for semiconductor production innovations. The shortage has been exacerbated by sharp increases in consumer electronics demand during the pandemic and the ever-growing demand for GPUs to train more complex AI models. Despite these setbacks, there have been significant AI hardware advancements between 2021 and 2023.
Measuring AI Hardware Progress
Before examining hardware advancements, it is essential to establish common performance measurement terminology. CPU power is typically assessed by transistor count, size of transistors in nanometers (nm), or clock speed in terahertz (THz). Accelerators like GPUs measure computational capacity, often termed “bulk compute,” in floating point operations per second (FLOPS) or integer-based operations per second (OPS). These units gauge the calculations a chip can perform in one second, with variants like TeraFLOPS/TeraOPS (trillion FLOPS/OPS), PetaFLOPS/PetaOPS (quadrillion FLOPS/OPS), and ExaFLOPS/ExaOPS (quintillion FLOPS/OPS). Also, total energy used (watts), energy efficiency (FLOPS/OPS per watt) and data transfer capability, measured in megabytes (MB), terabytes (TB), or petabytes (PB) per second, are important accelerator performance indicators.
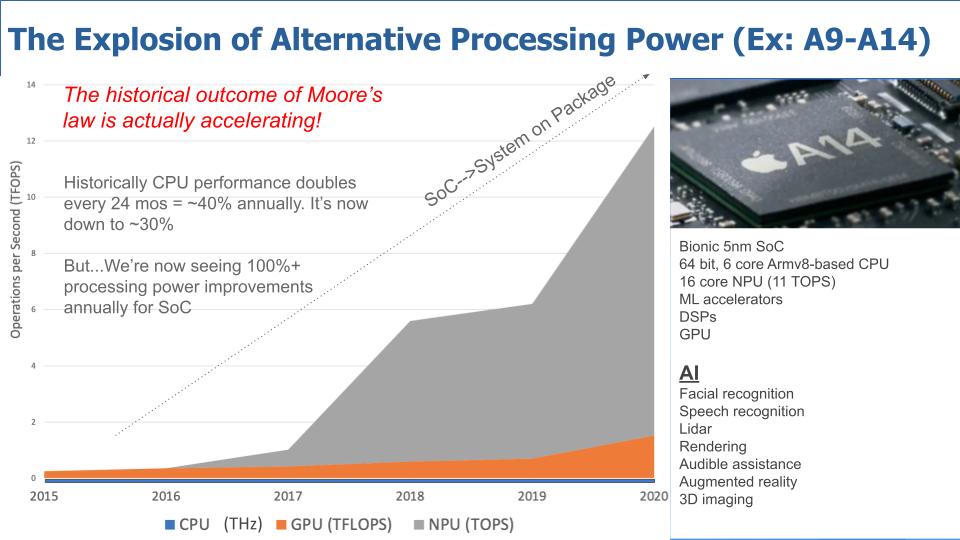
Using only CPU power or transistor count to compare hardware overlooks recent AI compute progress. For instance, Apple’s NPU or “neural engine” has seen over 100% annual improvements in bulk compute, surpassing both CPU and GPU growth. Figure 1a shows the historical processing power of Apple’s A-series iPhone System on a Chip (SoC) as well as the isolated CPU, GPU, NPU. The composition of the A14 SoC is shown in Figure 1b. The growth in bulk compute in the SoC, shown by the dotted line, is on an annual improvement pace of 118% since 2015 (Vellante & Floyer, 2021).
OpenAI identified three components reflecting AI progress in a 2018 study: algorithmic innovation, data, and training compute, with OPS as a crucial measure surpassing clock speed’s relevance (Amodei & Hernandez, 2018). Moore’s Law, correlating with the transistor count growth trend and ML advancement, shows signs of strain due to tech innovations. As the 2020s began, the tech community questioned Moore’s Law’s relevance, with MIT Technology Review’s “We’re Not Prepared for the End of Moore’s Law” (Hoffman, 2020) casting doubts. However, some suggested a broader Moore’s Law definition and more comprehensive metrics for computing advancements. Figure 2 shows the distinction of growth prior to and after 2012.
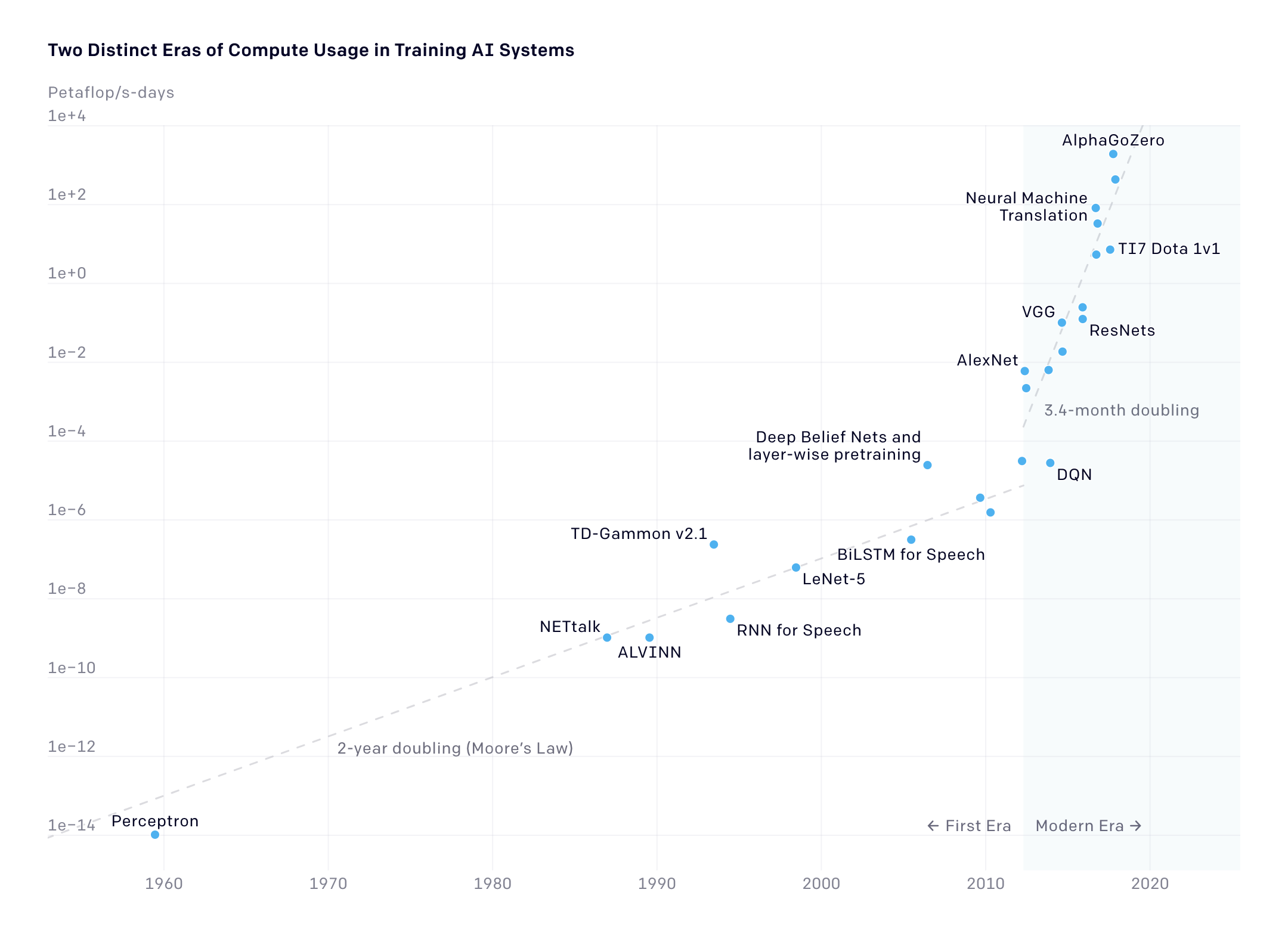
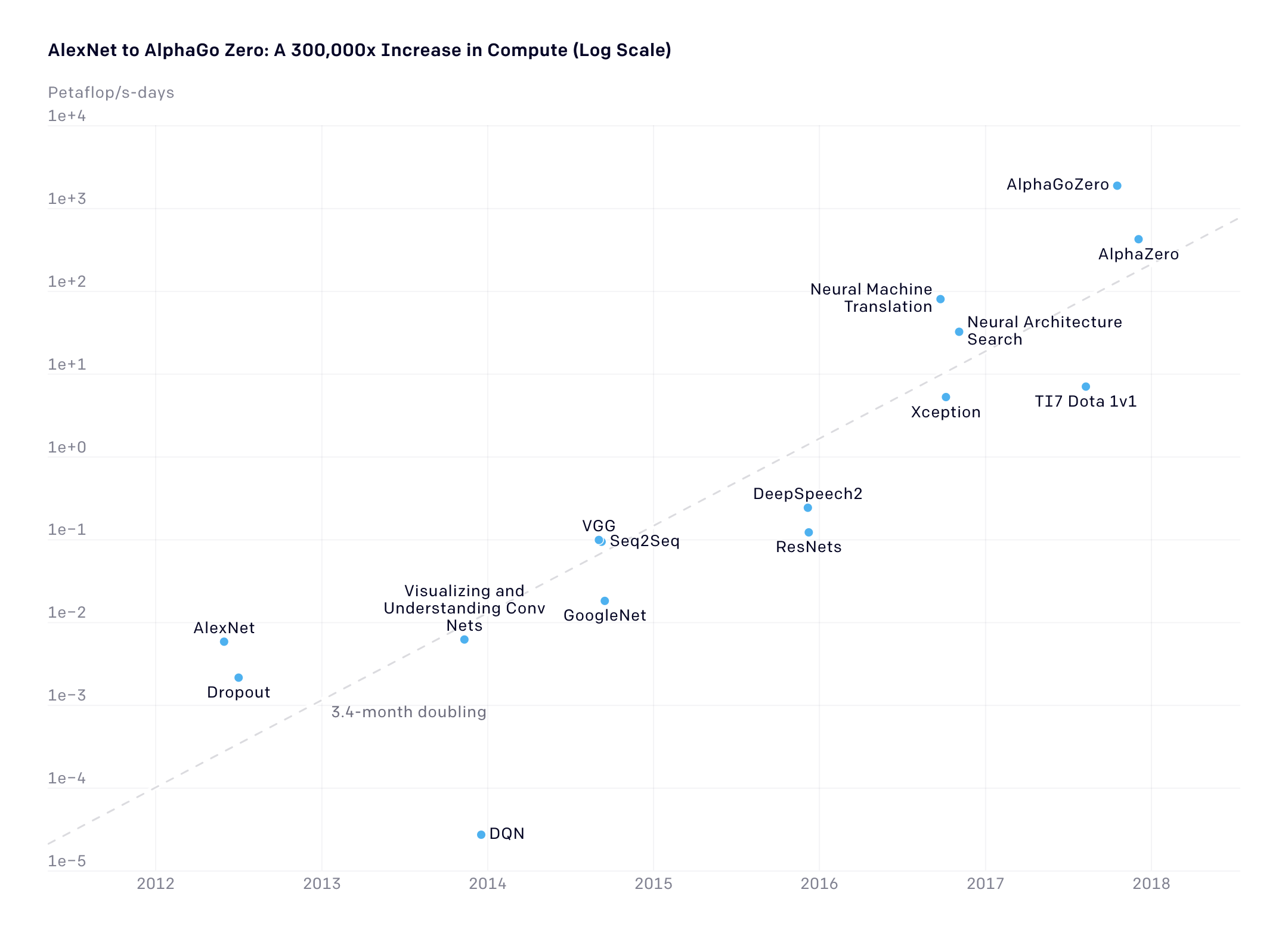
Figure 3 shows a closer look at AI models’ computational demand surpassing Moore’s Law since 2012. AI training compute soared by over 300,000 times with a 3.4-month doubling time (Amodei & Hernandez, 2018). The Moore’s law trend would have only doubled seven times in the same period of time. This indicates we are in a new AI compute evolution era, aligning with Sweeney’s ‘stacked exponential’ concept.
MLPerf: A Comprehensive Benchmarking Tool
In order to address the need for standard measurement of deep learning processors and accelerator performance, researchers from Baidu, Berkeley, Google, Harvard, and Stanford collaborated in 2018 to develop Machine Learning Performance (MLPerf). MLPerf is a set of benchmarks that evaluate the speed, scalability, power, and efficiency of ML software and hardware. Each benchmark is relevant to the specific requirements of each model or task, offering more comprehensive assessments of performance (Bunting, 2023).
Thought MLPerf was established in 2018, annual benchmark competitions were not standardized until the year 2020. In 2021, MLPerf v1.0 was officially introduced, featuring eight benchmark tests: image recognition, medical-imaging segmentation, object detection (two versions), speech recognition, natural-language processing, recommendation, and reinforcement learning. Commonly known as “the Olympics of machine learning,” more than 20 top hardware companies compete on these tests (Moore, 2022). The June 2022 MLPerf v2.0 benchmark results demonstrated a significant nine to ten times increase in training time performance compared to Moore’s law, as depicted in Figure 4 (Moore, 2022).

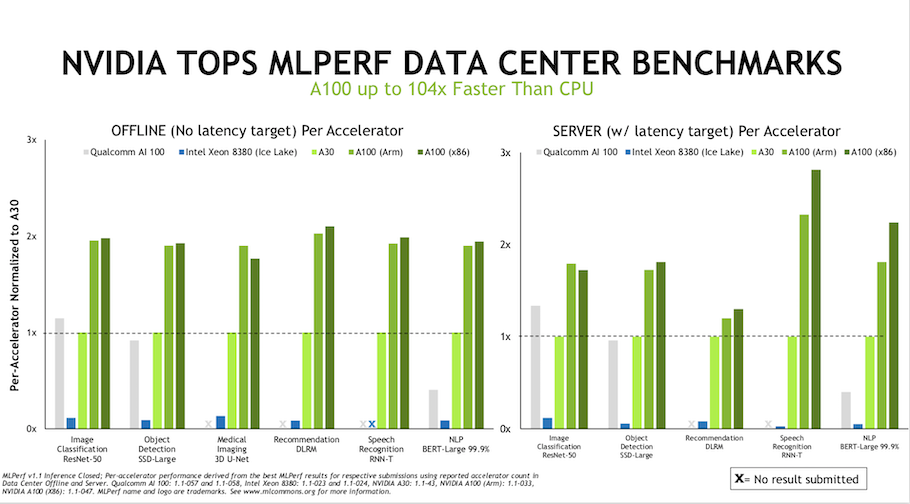
Nvidia has consistently submitted results for all eight benchmark tests, making it the main exemplar in the evolution of AI compute across the ML landscape. In 2022, Nvidia’s AI platform, powered by the A100 Tensor Core GPU, demonstrated exceptional versatility and efficiency in MLPerf. It achieved the fastest training time in four tests and the fastest performance per chip in six tests. This remarkable performance was attributed to innovations across GPUs, software, and scalability, resulting in a 23 times performance increase in just 3.5 years (Salvator, 2022). Figure 5a depicts the 2022 MLPerf results for the A100.
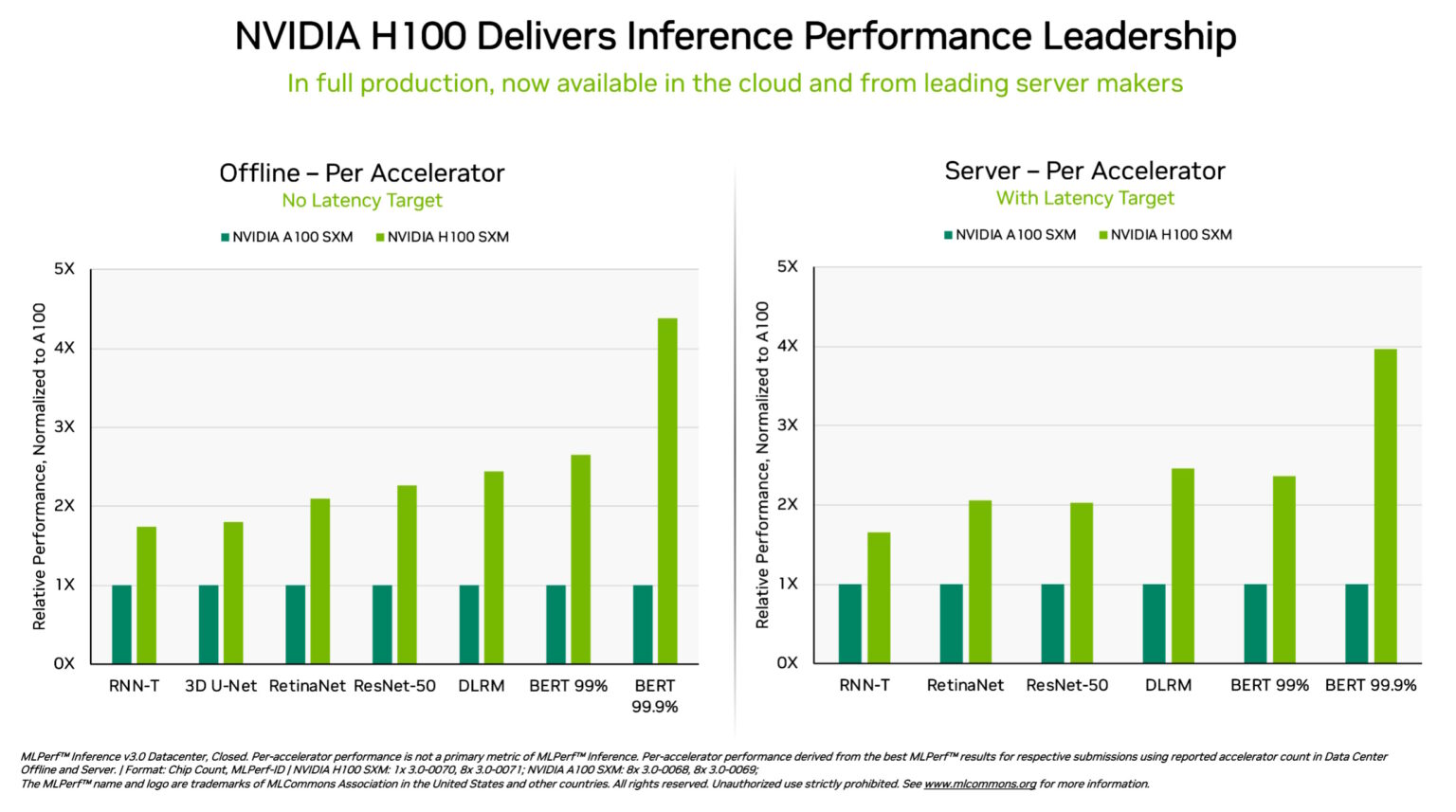
In the 2023 MLPerf tests (MLPerf v3.0), Nvidia’s AI hardware exhibited a substantial performance increase compared to 2022. The newly introduced Nvidia H100 Tensor Core GPUs were designed with AI contributions and run on DGX H100 systems. They not only achieved the highest AI inference performance across all tests but also demonstrated a performance gain of up to 54% since their debut in September 2022 (Salvator, 2023). Figure 5b showcases the 2023 MLPerf results for the H100 compared to the A100. Specifically, in the healthcare domain, the capability of H100 GPUs have improved on the 3D U-Net medical imaging benchmark by 31%. Additionally, the H100 GPUs powered by the Transformer Engine excelled in the Bidirectional Encoder Representations from Transformers (BERT) LLM benchmark, significantly contributing to the rise of generative AI (Salvator, 2023).
A Journey Through AI Hardware Advancements
The following sections provide a summary of significant hardware advancements in AI from 2021 to 2023 in chronological order. Key improvements are highlighted, and more technical details can be found in the accompanying summary tables. While exact timelines for each hardware advancement may vary, the focus is on showcasing progress based on widely acknowledged technologies with available data. Not all companies provide comprehensive information on chip capacities, which can limit the specific information available for each piece of hardware.
2021: An Unprecedented Leap
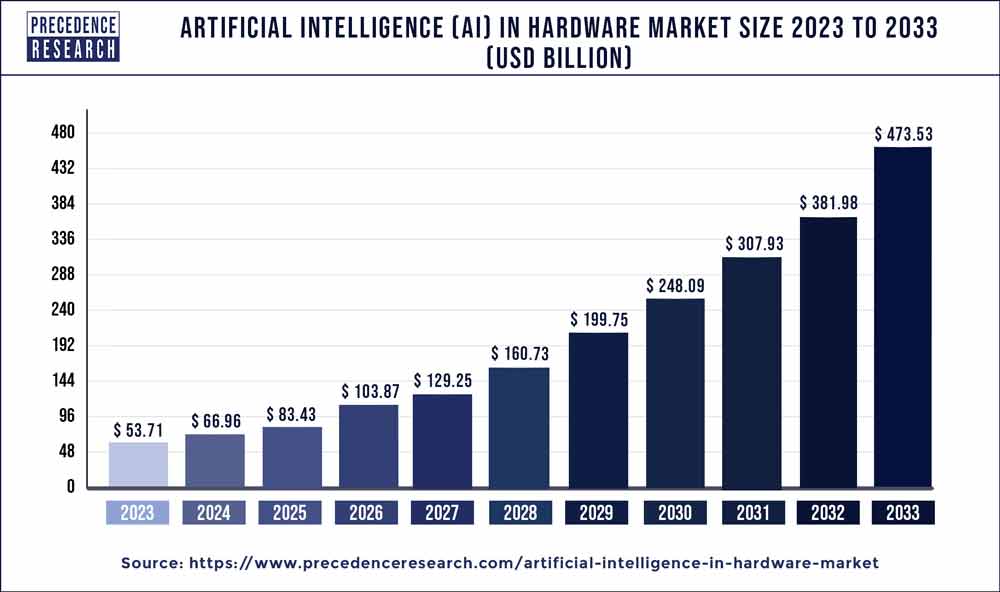
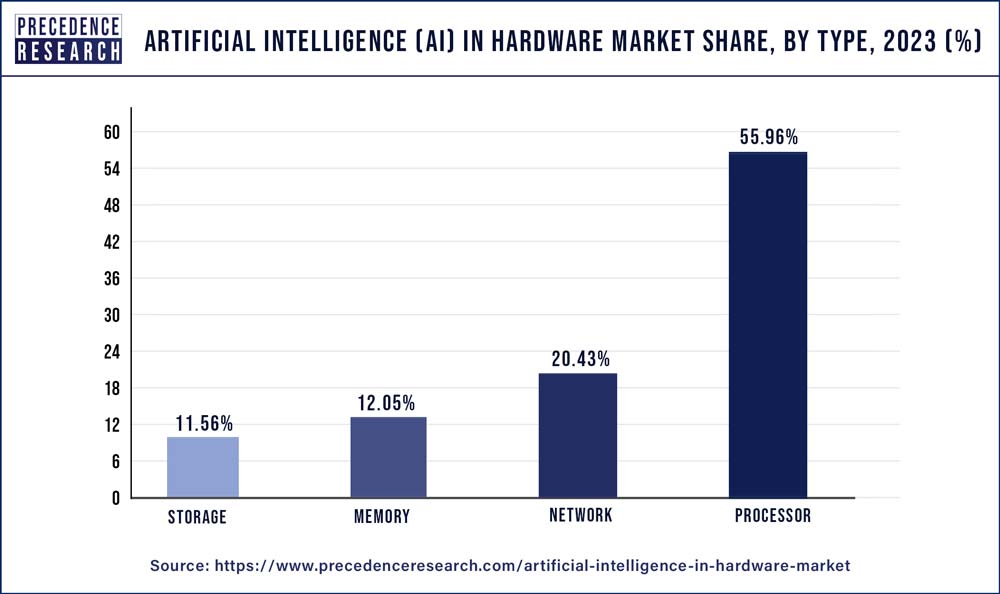
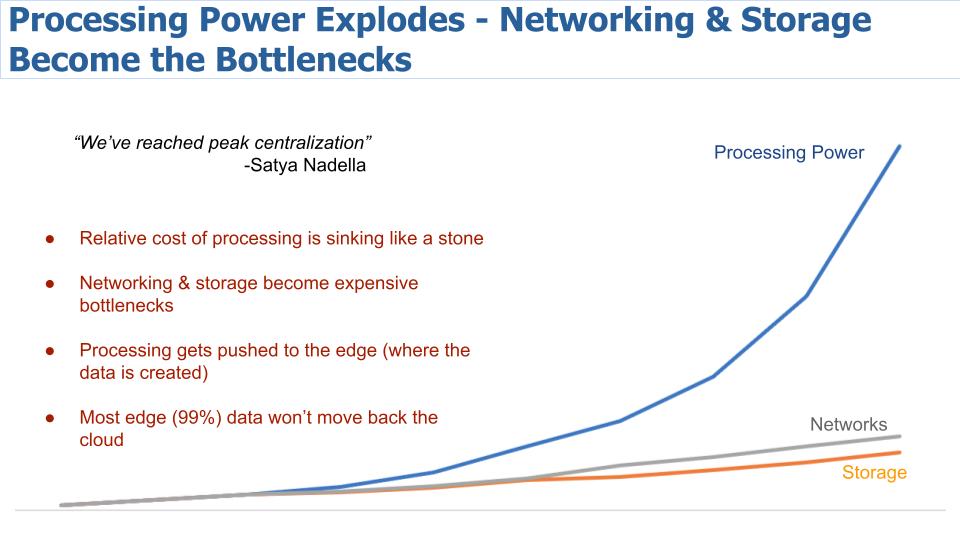
Investment in AI hardware development significantly increased in 2021, with the total capital invested globally almost doubling to $68 billion (Sharma, 2021). Precedence Research valued the 2021 AI hardware market at $10 billion, projecting growth to $90 billion by 2030 as shown in Figure 6 (Precedence Research, 2022). In 2021, the market demand for AI hardware was primarily driven by the need for more powerful processors, as depicted in Figure 7. This demand arose due to the significant divergence seen in the trajectories of compute power, which is vividly illustrated in Figure 8. Despite the limitations of storage and network compute power on the overall system’s capabilities, it was the processors that boosted system compute measured in OPS. Specialized processors and accelerators increasingly bypassed the need for network or storage hardware by optimizing data flow on-device. This reduced the reliance on transferring data over the network, resulting in more efficient and faster computation (Vellante & Floyer, 2021).
OpenAI
OpenAI launched DALL-E in January, a multimodal AI system generating images from text. Although not a hardware product by itself, its computational implications are vast, combining computer vision and natural language processing—two resource-intensive AI fields. Training and scaling the underlying models of DALL-E require considerable hardware resources to train OpenAI’s own third generation generative pretrained transformer model (GPT-3). Maintaining a production model like this requires enormous processing power, networking capabilities, and high-speed storage. While DALL-E’s exact hardware setup remains undisclosed, replicating it on smaller scales reveals the complexity of hardware setup (Cuenca, 2023).
Graphcore
In early 2021, Graphcore, a U.K.-based chip manufacturer announced its second generation of the Colossus intelligence processing unit (IPU), GC200 Colossus MK2. The GC200 is designed for a higher level of parallel processing capability to effectively manage the sparsity and irregularity of ML workloads, providing a different approach to the more common Nvidia’s GPUs (Doherty, 2021).
Cerebras Systems
In April, Cerebras Systems, a renowned AI chip startup, released the WSE-2 the largest chip ever built. The capacity more than doubles that of its predecessor, the WSE-1 (Dilmengani, 2023). Cerebras also announced the “world’s first brain-scale” AI solution. This term stems from the estimate that the human brain has an order of 100 trillion synapses and prior to this, existing AI clusters could match about 1% of that size. The CS-2 accelerator that is the size of a small refrigerator, supports models of over 120 trillion parameters but is comprised of only one WSE-2 chip (Business Wire, 2021).
Nvidia
The Nvidia Grace CPU, announced in April, was the company’s first data center CPU designed to address the computational requirements of advanced applications such as natural language processing, recommender systems, and AI supercomputing with large datasets. Grace combined energy-efficient Arm CPU cores with a unique low-power memory subsystem to deliver high performance with remarkable efficiency. This Arm-based processor aimed to provide a 10-fold performance increase for systems training large AI models, compared to leading servers at the time. Notably, the Swiss National Supercomputing Centre and the U.S. Department of Energy’s Los Alamos National Laboratory have plans to build Grace-powered supercomputers to support scientific research efforts (Nvidia, 2021).
In May, Google announced the introduction of their fourth-generation TPUs, for AI and ML workloads. TPUs, designed specifically to optimize AI computation, stood as Google’s response to the rising dominance of GPUs. Google further documented the performance gains of the TPU v4 this year, offering a staggering 10 times increase in ML system performance compared to its predecessor, TPU v3. With innovative interconnect technologies and domain-specific accelerators, the TPU v4 not only amplifies performance, but it also champions energy efficiency. Notably, the TPU v4 is engineered for large language models (LLMs) such as Google’s Pathways Language Model (PaLM), delivering 57.8% of peak hardware floating-point performance over 50 days of training on the TPU v4 (Jouppi & Patterson, 2022).
The following month Google published a paper in the journal Nature detailing their approach to using AI for the floor planning stage of chip design (Mirhoseini et al., 2021). This paper was the formalization of their 2020 blog post about AI powered chip design and made the findings more transparent. They also revealed that their fourth generation TPU, released just one month earlier, was designed using this new deep reinforcement learning technique (Vincent, 2021).
HPE, AMD, and Nvidia
The month of May also featured an announcement from Berkeley Lab’s National Energy Research Scientific Computing Center, Hewlett Packard Enterprise (HPE) in collaboration with Advanced Micro Devices (AMD) and Nvidia completed the Perlmutter supercomputer. It has since been instrumental in mapping the visible universe spanning 11 billion light years by processing data from the Dark Energy Spectroscopic Instrument. Early benchmarking has revealed up to 20 times performance speedups using the GPUs, reducing required compute time from weeks or months to merely hours (Trader, 2021).
Mythic
In June, Mythic announced the M1076 AI processor, which can store up to 80 million weighted parameters. This means that it can run complex AI models without the need for external memory (Mitchell, 2021). The M1076 required 10 times less power than a conventional system-on-chip or GPU. This introduction marked a shift towards creating more energy-efficient hardware solutions for AI, an important consideration as energy costs and environmental impacts become more of a concern (Sharma, 2021).
Cadence
Following the excitement of AI powered chip design in June, July brought the release of the Cerebrus platform from Cadence. The Cerebrus Intelligent Chip Explorer tool leverages ML to enhance the process of chip design, making engineers remarkably more productive. The introduction of ML has added an additional layer of automation to the design process, resulting in up to 10 times improved productivity per engineer and yielding a 20% enhancement in power, performance, and chip area (Takahashi, 2021).
SambaNova Systems
In August SambaNova Systems, another popular chip startup, announced a unique Dataflow architecture, a high-performance and high-accuracy hardware-software system designed for AI applications. The Dataflow architecture is powered by its innovative Cardinal SN10 reconfigureable data unit chip boasting an incredible 300 TeraFLOPS and up to 150 TB/s on-chip memory bandwidth. These high-speed compute capabilities are particularly relevant in the context of ML and AI (Kennedy, 2021).
Tenstorrent
Canadian based startup Tenstorrent released their flagship Grayskull processor into production in late 2020. It was not until Hot Chips 33 in August that it got its true debut. The Grayskull is referred to as an “all-in-one” computer system. In preliminary experiments, the system hit 368 TeraOPS and had been observed processing up to 23,345 sentences per second using Google’s BERT-Base language model for the SQuAD 1.1 data set, giving it a 26 times performance advantage over existing solutions (Wiggers, 2020).
Apple
In October, Apple further upgraded the M1 series chips—released just a year prior and hailed as Apple’s most powerful chips. The M1 Pro and M1 Max chips featured a standard but enhanced 16-core NPU for better on-device ML, highlighting Apple’s focus on integrating ML in their products (“Introducing M1 Pro and M1 Max,” 2021). Although not a traditional AI pioneer, Apple is emphasizing Edge AI, deploying AI applications on physical devices rather than relying on centralized cloud servers.
AWS
Amazon Web Services (AWS) continued hardware announcements during their annual Re:Invent conference in November. Among these was the third generation of their Graviton hardware, Graviton3. This latest version is three times faster for ML workloads and up to a 60% energy saving compared to other leading hardware, giving it the “best price-performance ratio in Amazon EC2” (Nikita, 2022).
Groq
Although not released in 2021, the startup called Groq, received significant of attention in late 2021 when it announced that their flagship GroqChip or Groq tensor streaming processor (TSP) was used for COVID drug discovery at Argonne National Laboratory. They showed a 333-fold speed improvement compared to legacy GPUs at the time (Westfall, 2021). This chip is highly specialized for ML workloads and not much else, capable of 1 PetaOPS performance on a single chip implementation (Garanhel, 2022).
Table 1. Hardware Summary 2021
| Company | Hardware | Key Features |
|---|---|---|
| Apple | M1 Pro/Max Chip | 16-core NPU optimized for Edge AI/ML acceleration, 11 TeraOPS |
| AWS | Graviton3 | 60% energy savings, 3x faster for ML workloads |
| Cadence | Cerebrus Platform | Platform for AI assisted chip design |
| Cerebras Systems | Wafer Scale Engine 2 (WSE-2) | 2.6 trillion 7nm transistors, 850,000 cores, 20 PB/s, 1 PetaFLOP, largest chip ever built |
| Cerebras Systems | CS-2 'brain-scale' Accelerator | Supports models up to 120 trillion parameters, contains 1 WSE-2, 13.5 million AI-optimized cores, 500kW |
| TPU v4 | TPU with 275 TeraFLOPS, 1.1 PB/s, 2 TeraOPS/W (3x FLOP/W vs v3), designed for Google's data centers, AI aided design | |
| AI Powered Chip Design | AI for floor planning stage of chip design using reinforcement learning | |
| Graphcore | GC200 IPU | 2nd Gen, 59 Bn transistors, 250 TeraFLOPS (double previous MK1), 62 TB/s, 0.57 TeraFLOP/W |
| Groq | GroqChip/Groq TSP | 1 core, 1 PetaOPS, 333x speed improvement over leading GPUs |
| HPE, AMD, Nvidia | Perlmutter Supercomputer | Supercomputer with 6,159 Nvidia A100 GPUs and 1,500 AMD Milan CPUs, 180 PetaOPS standard, 4 ExaFLOPS AI |
| Mythic | M1076 | 25 TeraOPS, up to 80 million weighted parameters, 10x less power than conventional GPU |
| Nvidia | Grace CPU | 4nm transistors, 144 cores, up to 1 TB/s, 7.1 TeraFLOP, 10x model training speed |
| OpenAI | DALL-E | End-to-end text-to-image generative model at scale, 12B parameter version of GPT-3 |
| SambaNova Systems | Cardinal SN10 | 300 TeraFLOPS and up to 150 TB/s memory |
| Tenstorrent | Grayskull | 368 TeraOPS, 23k+ sentences per second with BERT, 75/150/300W versions, 384 GB/s |
Source: (In row order) (Apple, 2021; Nikita, 2022; Peckham, 2022; Dilmengani, 2023; Business Wire, 2021; Jouppi & Patterson, 2022; Jouppi & Patterson, 2022; Doherty, 2021; Garanhel, 2022; Trader, 2021; Garanhel, 2022; Nvidia, 2021; Cuenca, 2023; Wiggers, 2020; Takahashi, 2021).









2022: Going Mainstream
Nvidia
In March, Nvidia announced the release of their general-purpose GPU server station lineup, DGX-1, and DGX-2 built on state-of-the-art Volta GPU architecture (Gupta, 2022). The system includes the DGX A100, which is a single server system featuring multiple A100 GPUs. Since 2020, the A100 has served as the industry standard for GPU hardware, which often prompts comparison when new hardware is released. Nvidia also announced the release of the H100 data center GPU, built with the new Hopper architecture with scalable speed in exchange for lower numerical accuracy. All these components are specifically designed for deep learning training, accelerated analytics, and inference (Fu, 2022).
Only one year after Google published their research into AI chip design, Nvidia announced their own incorporation of AI called ‘PrefixRL’. Similar methods of reinforcement learning were incorporated into their new Hopper architecture resulting in circuits 25% smaller than those designed by humans (Roy, Raiman, & Godil, 2023). In late 2022 Nvidia announced major upgrades to their consumer GPU, the new GeoForce 40 series (Walton, 2023).
Apple
In March and June, Apple announced the M1 Ultra and M2 chip, both next-generation enhancements of their breakthrough M1 chip. The M1 ultra contained the greatest number of transistors ever on a personal computer. The new mac standard NPU in M2 is approximately 40% faster than the prior year in every category (“Apple unveils M2,” 2022). These advancements showed Apples continued emphasis for on-device ML and more consistent performance across all types of Apple devices.
Intel
In May, Intel’s Habana Labs released the second generation of their deep learning processors for training and inference — Habana Gaudi2. Initial results show quicker training times for BERT in MLPerf benchmarks (Gupta, 2022).
Cadence
In June, Cadence announced that customer adoption of the Cerebrus platform was growing. They shared that a company called MediaTek, who powers more than two billion connected devices around the world, has integrated Cerebrus into production. (Business Wire, 2022). Cadence also launched JedAI, a platform that integrates the various specialized AI hardware phase design products into one platform (Freund, 2023).
HPE and AMD
June marked a groundbreaking collaboration between HPE and AMD, resulting in the Oak Ridge National Laboratory announcing the Frontier supercomputer, which is powered by AMD hardware. Notably, the Frontier is the world’s first officially recognized exascale supercomputer, having sustained 1.102 ExaFLOPS on 64-bit operations during an early benchmark test. Impressively, initial evaluations have recognized the Frontier’s architecture as the world’s most power-efficient and have dubbed it the “fastest AI system on the planet” (Alcorn, 2022).
IBM and Tokyo Electron
In July, IBM and Tokyo Electron made strides in 3D chip stacking by addressing the limitations posed by Moore’s law. Silicon carrier wafers, a significant obstacle in 3D chip manufacturing, were at the core of their challenges. The advancements they have introduced are designed to optimize the production process, with the added advantage of potentially alleviating the global chip shortage (Peckham, 2022).
Untether AI
In August, Untether AI introduced a device codenamed ‘Boqueria,’ also known as SpeedAI240. This device is designed to enhance energy efficiency and density, allowing scalability for devices of different sizes. Scalability of chip performance proves useful when working with language models of varying parameter sizes (Burt, 2022).
Tesla
On AI Day in September, Tesla revealed its powerful Dojo chip, designed for faster training and inference in self-driving cars. The Dojo chip is so powerful that it “tripped the power grid in Palo Alto” (Lambert, 2022). Tesla claims that one Dojo chip can replace six GPUs. The Dojo chip is expected to increase Tesla’s ability to train neural nets using video data, which is in high demand in their self-driving car initiative.
SambaNova Systems
In October, SambaNova Systems announced the shipping of the second generation of the DataScale system—SN30. The system, powered by the Cardinal SN30 chip, is built for large models with more than 100 billion (B) parameters and capable of handling both 2D and 3D images (Fu, 2022). The DataScale SN30, eight SN30 chips, boasts six times faster GPT training than the Nvidia DGX A100 system (Butler, 2022).
AWS
In October, AWS announced the general availability of Amazon EC2 Trn1 instances, which are powered by AWS Trainium chips, built specifically for training high-performance ML applications in the cloud. Trn1 instances claimed up to a 50% cost savings over comparable GPU-based EC2 instances for training LLMs (AWS, 2022).
A month later, at AWS Re:Invent 2022, Amazon made the EC2 Inf2 powered by the AWS Inferentia2 generally available. This ML accelerator, optimized for inference, offers larger compute density enabling lower cost per query. Inf2 also boasts the ability to deploy a 175B parameter model, such as GPT-3, on a single server. These two chip architectures represent a shift from using general purpose hardware to using hardware custom-built to the specific phase of the system in order to lower task-specific compute costs (Liu, 2022).
Cerebras
In November, Cerebras Systems launched their AI supercomputer, Andromeda, aiming to accelerate academic and commercial research (Gupta, 2022). Cerebras emphasized a concept called ‘near-perfect linear scaling.’ This means that when the system’s resources are doubled, for instance by using two WSE-2 chips instead of one, the performance or speed of processing can also be expected to double (Hall, 2022).
IBM
November also marked the launch of IBM’s AIU chip. This unique chip confines GPU floating point operations to 8-bit, less precise than even a CPU with higher compute density and similar model accuracy. Furthermore, it demands less power and memory compared to other top-tier GPUs with identical measures. The primary advantage lies in its affordability. Priced around $1,000 per chip, a set of 10 AIUs could rival the performance of the Nvidia H100 GPU, which ranges from $20,000 to $30,000. IBM believes this platform will make model training 1,000 times faster by 2030 (Morgan, 2022).
OpenAI
OpenAI’s November release of ChatGPT underscored the key role of hardware in AI performance. Training the GPT-3 on 10,000 Nvidia A100 GPUs facilitated managing the 175B parameters and 45 TB dataset in a reasonable time. Moreover, real-time inference demands powerful servers for model hosting and efficient hardware for quick request processing. Despite high upfront costs, their large-scale infrastructure setup enables a low per query cost of 0.36 cents (Patel & Ahmad, 2023). However, at around $10,000 a piece for each GPU it is estimated that the training cost for GPT-3 was around $4 million (Vanian & Leswing, 2023).
Contrast this with the April release of DALLE-2, OpenAI’s upgraded image generation tool. DALLE-2 uses a technique called ‘stable diffusion’ which eliminated the need to train GPT-3. A recent report suggested that the training of DALLE-2 only required a cluster of 256 A100 GPUs and 150,000 hours of training which equates to about $600,000 (Bastian, 2022). The downside is that training stable diffusion requires more training data. DALLE-2 is a significant example of how a simplified model architecture enabled greater efficiency without a change in GPU type.
Table 2. Hardware Summary 2022
| Company | Hardware | Key Features |
|---|---|---|
| Apple | M1 Ultra, M2 | M1 Ultra - 114 Bn transistors, 32 NPU cores (double previous), 22 TeraOPS, M2 - 20 Bn 5nm transistors, 40% faster standard NPU, 15.8 TeraOPS |
| AWS | EC2 Trn1, EC2 Inf2 | Cloud Trn1 clusters - up to 3 PetaOPS, Inferentia clusters - up to 2.3 PetaOPS, 10x lower latency |
| Cadence | MediaTek Integration, JedAI | 10x increased chip engineering productivity, 60% improvement in timing |
| HPE, AMD | Frontier Supercomputer | 1.102 ExaFLOPS (64-bit), 6.88 ExaFLOPS (less precision), 52.23 GigaFLOPS/W, 29 MW, 37,632 AMD GPUs |
| Cerebras Systems | Andromeda Supercomputer | Combines 16 Cerebras CS-2 systems for academic and commercial research, 13.5 million cores, 1 ExaOPS, 120 PetaFLOPS dense compute |
| IBM | IBM z16, AIU | First Telum based system, 19 miles of wire, 22B 7nm transistors, 6 TeraFLOPS / 32 cores, 23 Bn 5nm transistors, 205 TeraFLOPS (8-bit operations), 820 TeraFLOPS (4-bit), low cost |
| IBM/T.E. | 3D Breakthroughs | 3D chip enabled silicon carrier wafers, switch from transistors per unit area into transistors per unit volume |
| Intel | Habana Gaudi2 | 24 tensor cores, built with 7nm technology, 2.45 TB/s, beats Nvidia A100 in MLPerf, 600W |
| Nvidia | DGX Station, DGX-A100, H100 data center GPU, GeoForce 40 Series GPU | 8 GPUs, Each with 312 TeraFLOPS, 54 Bn transistors, GPU memory of 640 GB / 80 Bn 4nm transistors, 60 TeraFLOPS (64-bit), 3 TB/s, 75% more power consumption. Designed with PrefixRL / Largest 76.3 Bn 4nm transistors, 60 TeraFLOPS (64-bit), 1 TB/s, 330.3 Tensor TeraFLOPS, 450W. |
| OpenAI | ChatGPT/GPT-3 System | Trained with 10,000 Nvidia A100 GPUs, inferenced with 3,617 servers, 28,936 A100 GPUs |
| OpenAI | DALLE-2 | Trained with 256 A100 GPU cluster, stable diffusion, improved cost structure |
| SambaNova Systems | Cardinal SN30 | 86 billion transistors, 688 TeraFLOPS (16-bit), fits model up to 100B parameters, 12.8x memory of Nvidia A100 |
| Tesla | Dojo Tile, D1 Chip | 25 chips/tile, 8,850 cores, 9 PetaFLOPS, 36 TB/s, 15 kW |
| Untether AI | Boqueria, speedAI240 | 2 PetaFLOPS (8-bit), 30 TeraFLOPS (64-bit), 30 TeraFLOPS/W, 1456 cores, 7nm transistor size |
Source: (In row order) (Apple, 2022; AWS, n.d.; Gwennap, n.d.; Alcorn, 2022; Fu, 2022; Morgan, 2022; Walton, 2023; Gupta, 2022; Fu, 2022; Peckham, 2022; Patel & Ahmad, 2022; Bastian, 2022; Business Wire, 2022; Hall, 2022; Lambert, 2022).









2023: A New Landscape
Apple, Google, and Microsoft
The 2023 developer conferences from Apple, Google, and Microsoft gave a preview of the types of advancements coming in the second half of the year and beyond. Google I/O, Microsoft Build, and Apple WWDC each highlighted primarily software upgrades that indicate the companies priorities. Microsoft is fully embracing and participating in the AI race with new virtual assistants, product features, Azure Supercomputer, and open LLMs (Porter, 2023). Many were surprised at the lack of a TPUv5 announcement at Google I/O given that it has been acknowledged to exist back in 2021 (Shah, 2023). Apple, a bit more withdrawn from the hype surrounding AI, did not once mention the term “artificial intelligence” at WWDC (Greenburg, 2023). Instead, they unveiled numerous software improvements for ML across the device ecosystem along with the upgraded M2 Ultra’s 32-core NPU touted as 40% faster than the prior year. (“Apple introduces M2 Ultra,” 2023).
Synopsis and Cadence
AI assisted chip design has resurfaced as a more popular option for manufacturers. Although there have not been any significant announcements made so far in 2023 regarding AI designed chips, Synopsys and Cadence have reported higher adoption of their intelligent design software. Specifically in February, Synopsys reported that it had reached 100 commercial “tapeouts” or 100 chips that are being used in commercial products (Ward-Foxton, 2023).
Groq
In March, Groq gained the spotlight by claiming that it had created a process to move Meta’s LLaMA from Nvidia chips over to its own hardware signaling a potential threat to Nvidia’s 90% GPU market share. The complexity of the current AI hardware makes it a tedious task to adapt model architectures to run quickly on new setups (Lee & Nellis, 2023).
Nvidia
The International Supercomputing Conference in May featured several major announcements from Nvidia. Their Grace CPU Superchips, now integrated into the UK-based Isambard 3 supercomputer, provides superior speed and memory bandwidth with its 55,000+ core count. These benefits stem from the incorporation of Arm Neoverse V2 cores (Kennedy, 2023). Nvidia’s DGX GH200 supercomputer is powered by a combination of the new Grace Hopper 200 GPU and the Grace CPU, with features like 144 TB of shared memory, marking an almost 500-fold increase compared to the previous generation DGX A100. A standard cluster of 256 such configurations offers a staggering 1 ExaFLOP (Edwards, 2023).
Intel
In May, Intel announcing embedded Vision Processing Units (VPUs) across all variants of Meteor Lake chips, thereby offloading AI processing tasks from the CPU and GPU to the VPU. This move resulted in increased power efficiency and ability to manage complex AI models, providing benefits for power-hungry applications such as Adobe suite, Microsoft Teams, and Unreal Engine (Roach, 2023). Intel also introduced the fourth generation Xeon processors with ten times speed improvement for PyTorch training/inference. The update Xeon series offers optimized models for high-performance, low-latency networks and edge workloads (Smith, 2023).
Meta
Meta made its leap into AI hardware in May by unveiling its first custom-designed chips, the Meta Training and Inference Accelerator (MTIA) and the Meta Scalable Video Processor (MSVP). These chips, optimized for deep learning and video processing, underpin Meta’s plans for a next-gen data center optimized for AI, illustrating its dedication to crafting a fully integrated AI ecosystem (Khare, 2023).
AMD
AMD introduced an AI chip in June called MI300X, described as “the world’s most advanced accelerator for generative AI” (Mohan, 2023). This introduction was expected to compete head-on with Nvidia’s AI chips and generated interest from major cloud providers. Simultaneously, AMD initiated high-volume shipping of a general-purpose central processor chip named “Bergamo”, adopted by Meta Platforms and others for their computing infrastructure (Mohan, 2023).
Inflection AI
In July, the startup Inflection AI, which aims to create a “personal AI for everyone,” made a major announcement in their quest to develop a chatbot called “Pi”. The company plans to equip an AI supercomputer with 22,000 Nvidia H100 GPUs. This supercomputer could allow their infastructure to compete with the AMD Frontier supercomputer and enable significant improvements to their ‘Inflection 1’ LLM. Interestingly, the key point of discussion is not so much the computing power itself, but whether Nvidia can meet such a substantial GPU order. This comes amid recent reports suggesting difficulties in acquiring even a single H100 unit in addition to the ongoing chip shortage (Zuhair, 2023).
More To Come
While the advancements thus far in 2023 are significant, it is important to note that the main AI Hardware conferences such as AI Hardware Summit, AWS Re:Invent, Hot Chips, and others are yet to occur. As of July 2023, there is not a full picture of all the developments in the field for 2023. As such, the information about the current state of AI hardware in 2023 is still limited.
Table 3. Hardware Summary 2023
| Company | Hardware | Key Features |
|---|---|---|
| AMD | MI300X AI Chip and Bergamo Processor | 153 billion transistors, up to 40 billion parameter model in memory, 2.4x memory density H100 |
| Apple | M2 Ultra | 32-core 40% faster NPU, 31.6 TeraOPS, 134 billion 5nm transistors, 192 GB capacity |
| Google (BARD), Microsoft (Bing AI) | Interactive LLMs and Assistants | Large-scale models designed for interactive and responsive tasks, leveraging the power and efficiency of the latest AI acceleration hardware |
| Groq | GPU Model Migration | Capable of quickly migrating Meta's LLaMA off Nvidia GPUs |
| Inflection AI | LLM Supercomputer | 22,000 H100 GPUs, 700x4 Intel Xeon CPUs, $ 1 billion price tag, 31 MW |
| Intel | Meteor Lake chips with VPUs | VPU meant for sustained AI and AI offload with reduced power consumption |
| Intel | Xeon v4 | 14 cores, 135W, 7.2 billion transistors, 10x speed improvement for PyTorch models. |
| Meta | Meta Training and Inference Accelerator (MTIA) and Meta Scalable Video Processor (MSVP) | MITA - 51.2 TeraOPS, 25 W, 800 GB/s |
| Nvidia | Nvidia Grace CPU Superchips | 384 Arm-based Nvidia Grace CPU Superchips, >55,000 cores, FP64 performance, 270 kW power consumption, Arm Neoverse V2 cores |
| Nvidia | Nvidia DGX GH200 | 528 GPU tensor cores, 4 TB/s memory bandwidth, 144 TB of shared memory with linear scaling, 18,432 cores, 256 GPUs, 1 ExaFLOPS, 144 TB unified memory with linear scaling |
Source: (In row order) (Ray, 2023; Apple, 2023; Vanian & Leswing, 2023; Ray, 2023; AleksandarK, 2023; Alcorn, 2023; Smith, 2023; Fu, 2022; Kennedy, 2023; Edwards, 2023).








Greater Pace: Prospects and Challenges
The late 2022 release of OpenAI’s ChatGPT sparked a surge in AI advancements over the following six months, primarily fueled by an increased demand for hardware related to generative AI and LLMs. The competitive landscape, featuring key players like Google’s Bard powered by PaLM 2, Microsoft’s Bing AI, and Meta’s LLaMA, were driven by the rapid development of LLMs in response to an explosion of demand. Training quality LLMs required the most advanced AI hardware; however, hardware is just one facet of product development. Choices about parameter and data size critically shape the design, affecting everything from hardware requirements to training duration and model performance. For instance, the implications of choosing 175B parameters for OpenAI’s GPT-3, 1.8 trillion for GPT-4, versus LLaMA’s 65B parameters are considerable.
The surge in demand from LLMs and other generative AI applications has disrupted the GPU market because these sectors have not been included in historical market projections. The resulting shortage has prevented GPUs from becoming less expensive, which has further impeded the entry of smaller companies into the market and inhibited the widespread adoption of acceleration hardware. The heightened demand even creates challenges for cutting-edge companies like OpenAI, who are experiencing deployment bottlenecks due to GPU shortages. This scarcity is the reason only 37% of the 500 most powerful computer systems globally are using GPUs. This indicates that the industry is leaning towards alternative solutions for desired computational power, emphasizing other system components such as CPU-only solutions or innovative use of integrated GPUs (Eadline, 2023).
This fast-paced advancement towards advanced AI has stirred up a wide range of perspectives within the AI community on the long-term outlook. On one hand, prominent technology figures like Geoffrey Hinton, Elon Musk, and Eric Schmidt urge caution, highlighting ethical and long-term existential risks (Gairola, 2023). On the other hand, other prominent AI advocates such as Andrew Ng see the potential of superior AI driving unprecedented advancements and solving global challenges (Cherney, 2023). As these modern figures grapple with uncertainty regarding AI development, the pioneers of this field also reflected deeply on the implications of machine advancement.
Reflecting on the pace of technological progress following the Industrial Revolution and recent publication of Darwin’s ‘Origin of Species’, Samuel Butler (1863) expressed this observation in his essay, “There is no security against the ultimate development of mechanical consciousness, in the fact of machines possessing little consciousness now… Reflect upon the extraordinary advance which machines have made during the last few hundred years, and note how slowly the animal and vegetable kingdoms are advancing.” Butler’s words highlight the staggering speed of machine evolution, especially when compared to the slow, incremental changes seen in biological organisms.
Years later, Alan Turing echoed these sentiments. Turing (1951) reflected on the unpredictable nature of the technological advancements of his time, asserting, “We can see plenty there that needs to be done, and although we can make some fairly reliable, though quite rough, guesses, based on past experience, as to the order in which these developments will come, there remains the possibility that any one particular piece of research may lead to consequences of a revolutionary character.”
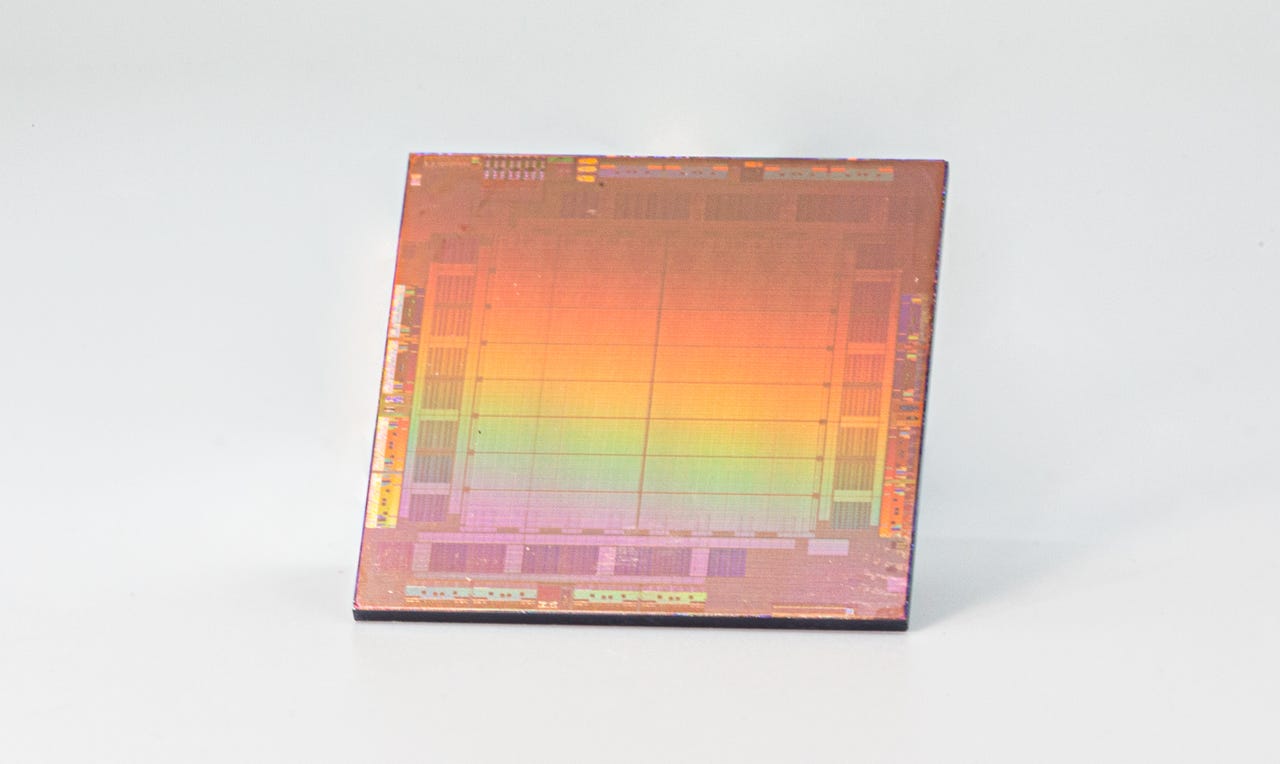
Whether or not machines will surpass human intelligence is an age-old question. The difference between the hype experienced now versus the 1970’s is that we have the compute capability to keep up with the hype, suggesting that we are not in a bubble that would lead to another “AI Winter”. As illustrated in Figure 12, a recent report from ARK Investment Management LLC (ARK) shows that Neural Networks, and subsequent training, have the most influential potential as a catalyst for a host of other technologies(ARK, 2023). Equally important, although not directly illustrated in the figure, is the process of training these networks, which by necessity accompanies their development and is a significant catalyst.
The process of training a model like GPT-3 is forecasted to become far less expensive by 2030 as illustrated in Figure 13 (ARK, 2023). AI training costs are currently dropping around 70% per year and are projected to continue at that same pace. A crucial point is that relative to GPT-3 level performance, the underlying factor here is a hardware cost improvement projection and not a model complexity projection.
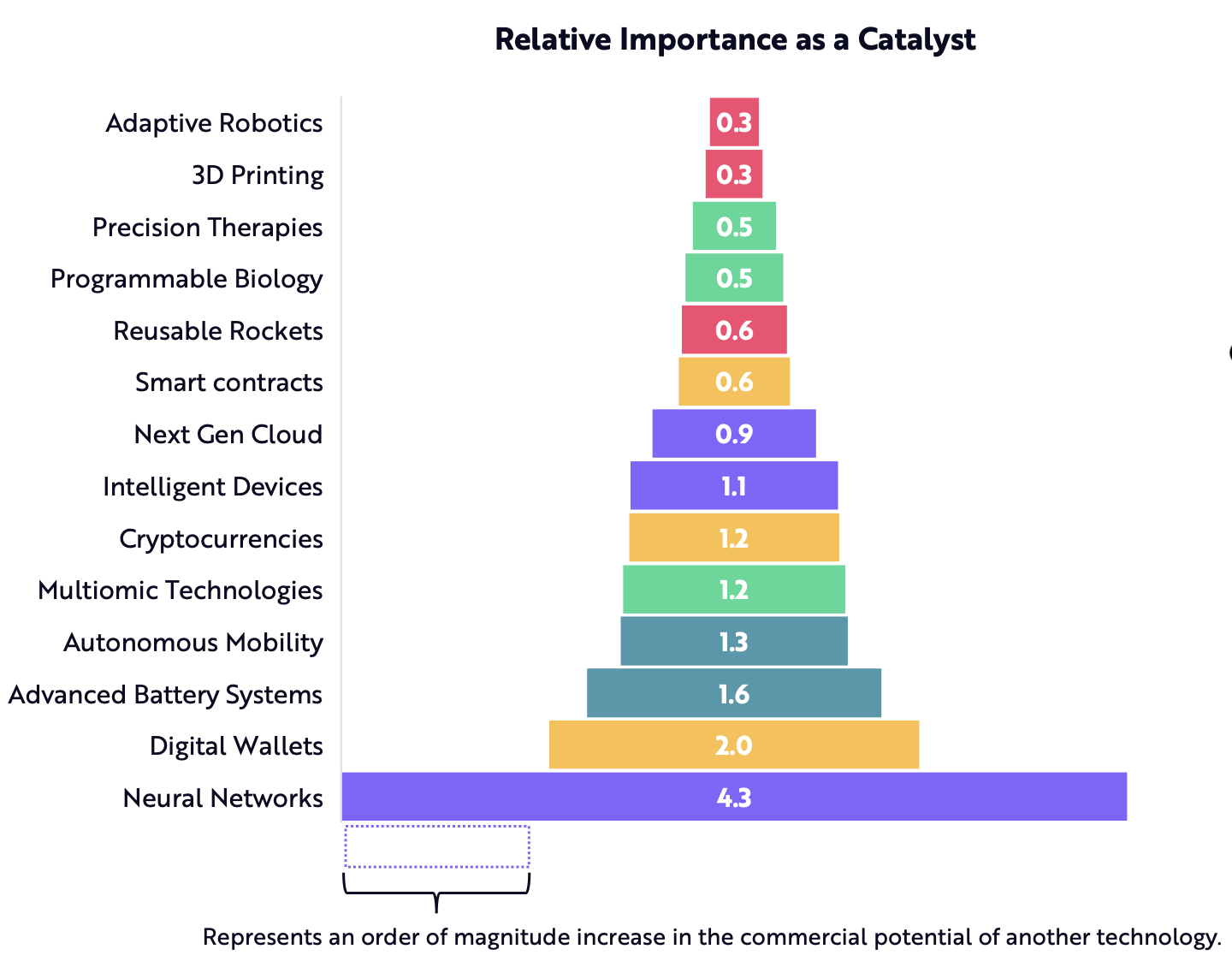
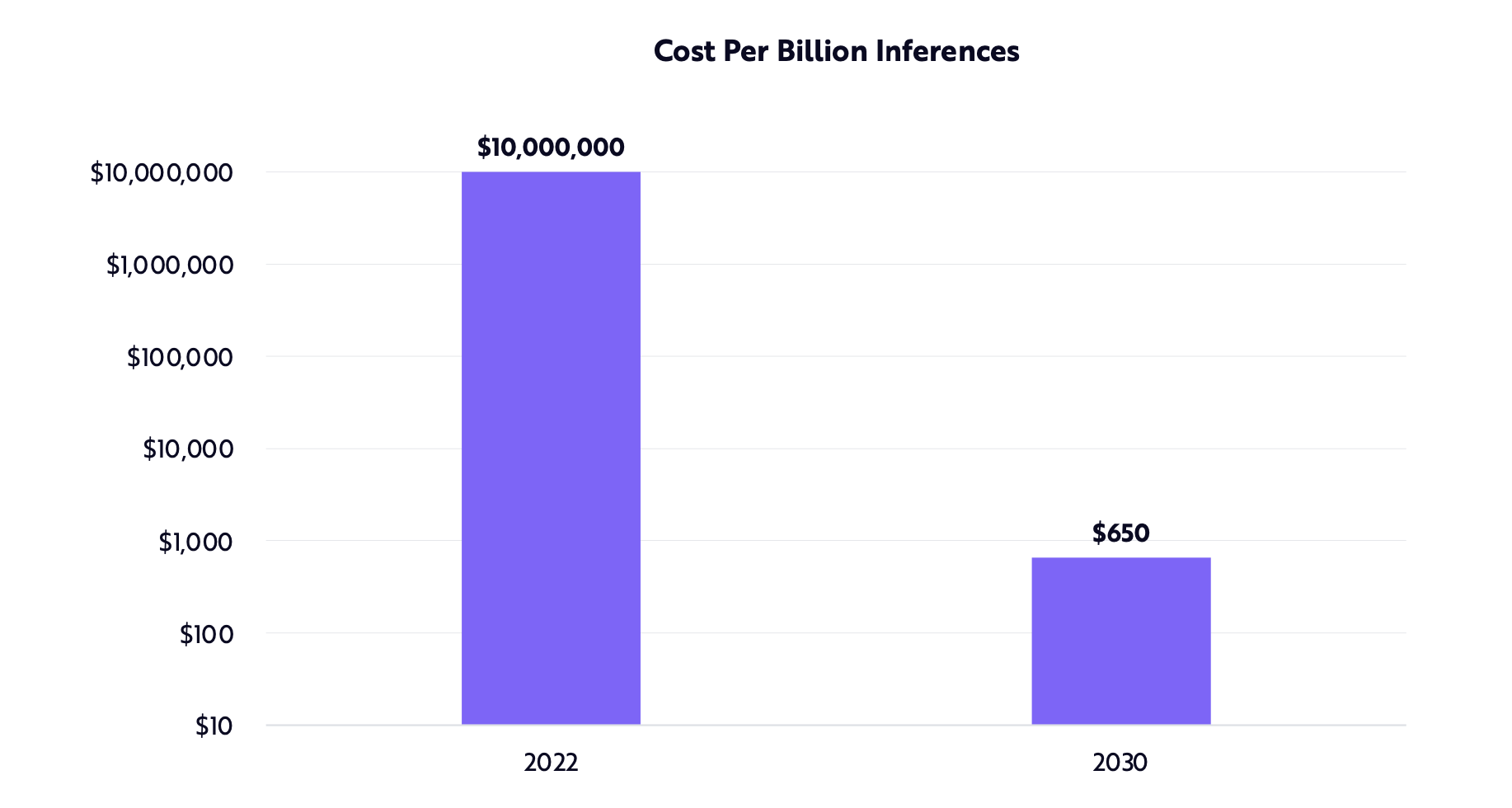
Despite the forecasted lower cost to train existing models like GPT-3, model complexity has already evolved far beyond this model that initially powered ChatGPT. As stated previously, GPT-3 is comprised of 175B parameters and was trained on 45 TB of data. The successor released in March 2023, GPT-4, contains 1.8 trillion parameters and was trained on 1 PB of data (E2Analyst, 2023). Any improvements in training cost for GPT-3 are now irrelevant due to the higher cost of data and much larger parameter size. A recent report by OpenAI analyzed training cost of recent AI models, such as GPT-4, and found that the cost of training is increasing exponentially as shown in Figure 14. The data shows that the cost of training a model is expected to rise to $500 million by 2030 (Cottier, 2023).
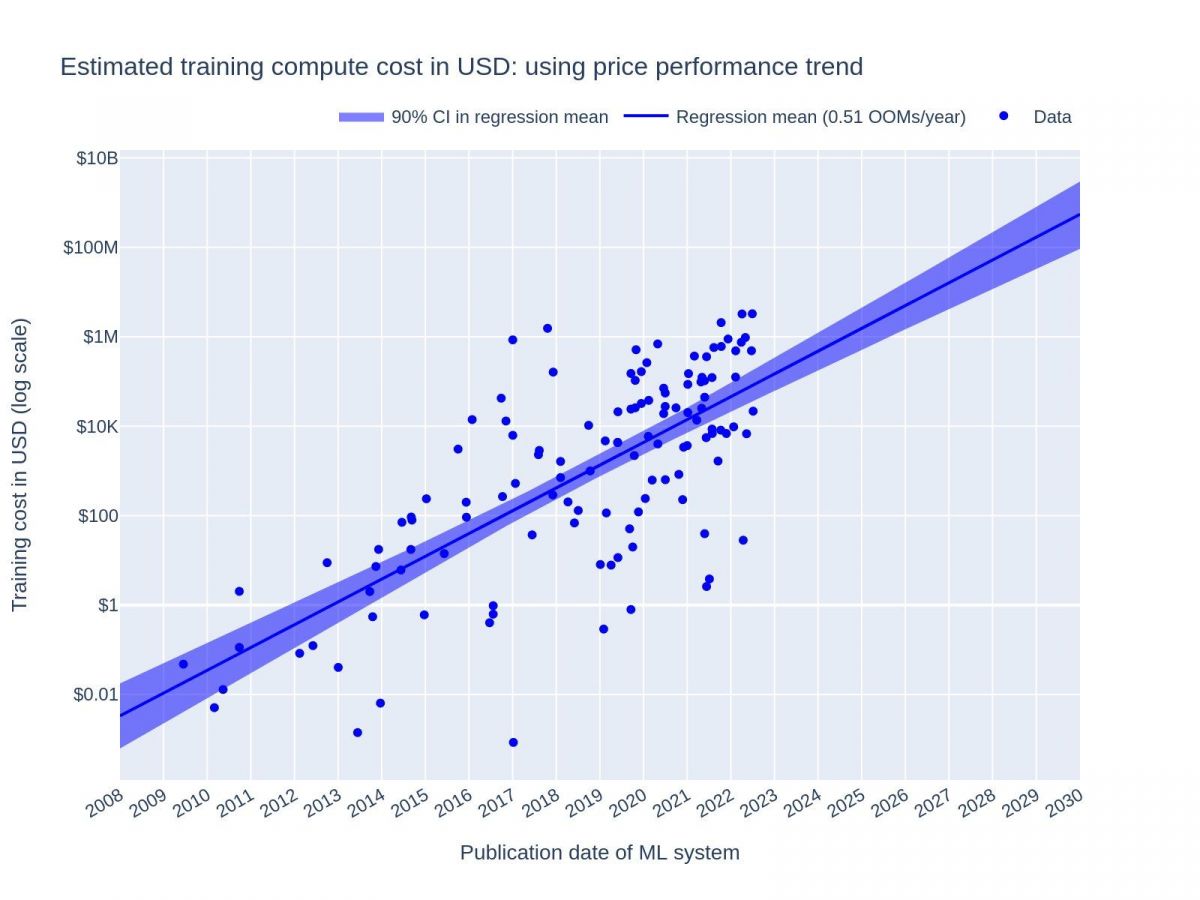
Though hardware shortages continue, and specialized GPUs remain expensive, a recent estimate by ARK shows the costs of AI hardware and software, when measured by relative compute unit, are declining as illustrated in Figure 15a. This combination of continued innovations will eventually enable applications like ChatGPT to run inferences at such a low cost that it can be deployable to the level of Google search according to the projection shown in Figure 15b (ARK, 2023).
What the Community Has Learned
The years since 2021 have proven to be historic for the development of AI-specific hardware, marking a notable departure from traditional computing paradigms. Advancements in processing and acceleration hardware are not solely about boosting raw performance or adhering strictly to Moore’s Law’s transistor-doubling prediction. Experimentation has been key during this period, leading to numerous technological breakthroughs, as well as a newfound understanding that incorporation of an expensive GPU does not guarantee success. Instead, the industry has shifted its focus towards specializing the GPU architecture for the required tasks such as training or inference, optimizing other components of the computer architecture, or building more specialized models to reduce hardware demand. The specialization of different components has led to experimentation with other architectures such as 3D chip stacking and “neuromorphic” chips designed to mimic the structure of the human brain (University of California - San Diego, 2022).
This paradigm shift is further emphasized by the rise of benchmarks like MLPerf. These are not simply nice-to-have performance metrics anymore; they are vital indicators of technological progress in AI. Rarely does a new CPU or GPU announcement come without some indication of MLPerf performance. These benchmarks reflect the nuanced performance characteristics of various AI workloads and provide invaluable context for ML practitioners. This paradigm shift is further emphasized by the rise of benchmarks like MLPerf. These are not simply nice-to-have performance metrics anymore; they are vital indicators of technological progress in AI. Rarely does a new CPU or GPU announcement come without some indication of MLPerf performance. These benchmarks reflect the nuanced performance characteristics of various AI workloads and provide invaluable context for ML practitioners. However, critics of MLPerf indicate that it is not comprehensive enough to capture the entire end-to-end lifecycle of an AI application. With only eight benchmark tests, manufacturers may be focusing too narrowly on training and inference while ignoring other crucial tasks for compute resources, such as data loading, model serving, and edge computing (Bunting, 2023).
Despite the criticisms, this culture of benchmarking has provided reassurance for the future of computing, dispelling any illusions of an impending “AI Bubble” akin to the 1970s and confirming that AI is firmly entrenched in our technological landscape. This recent period of advancements has tangible reductions in cost, widespread adoption of AI applications, and steady improvements in hardware capabilities.
One of the most important takeaways is the realization that more acceleration power is not the sole determinant of AI system performance. The evolution of LLMs like ChatGPT and other specialized models has clearly demonstrated that the true potential of AI is unleashed when there is harmony between the data, hardware, and the software that is specifically optimized for that hardware. This recognition has redefined the approach to AI development, democratizing access to intelligent systems, and broadening the AI audience. Product design decisions increasingly reflect this understanding, with flexibility catering to consumer needs taking precedence over rigid accelerators designed to manage specific problem types.
Lastly, this time period has highlighted that hardware is no longer the most restrictive bottleneck of AI performance. As AI algorithms become more efficient and hardware continues to advance, the challenges faced in harnessing the full potential of AI lie elsewhere. Issues such as data size, availability, quality, hardware power efficiency, and system integration are moving to the forefront. Ultimately, the advancements in AI acceleration hardware since 2021 have greatly enriched the ML community, enabling practitioners to achieve what was recently thought to be impossible. These developments will continue to empower model developers, enhance productivity, and illuminate new areas of research ripe for exploration. This begs the question: what perceived impossibilities will become possible by 2025?
References
Alcorn, P. (2022, June 2). AMD-Powered Frontier Supercomputer Breaks the Exascale Barrier, Now Fastest in the World. Tom’s Hardware. https://www.tomshardware.com/news/amd-powered-frontier-supercomputer-breaks-the-exascale-barrier-now-fastest-in-the-world
Alcorn, P. (2023, May 29). Intel details Meteor Lake’s AI acceleration for PCs, VPU unit. Tom’s Hardware. https://www.tomshardware.com/news/intel-details-meteor-lakes-ai-acceleration-for-pcs-vpu-unit
AleksandarK. (2023, July 3). Inflection AI Builds Supercomputer with 22,000 NVIDIA H100 GPUs. TechPowerUp. https://www.techpowerup.com/310783/inflection-ai-builds-supercomputer-with-22-000-nvidia-h100-gpus
Amazon Web Services. (2022, October 13). Introducing Amazon EC2 TRN1 Instances for High-Performance, Cost-Effective Deep Learning Training. https://aws.amazon.com/about-aws/whats-new/2022/10/ec2-trn1-instances-high-performance-cost-effective-deep-learning-training/
Amazon Web Services, Inc. (n.d.). Amazon EC2 Inf1 instances. Retrieved July 2, 2022, from https://aws.amazon.com/ec2/instance-types/inf1/
Amodei, D., & Hernandez, D. (2018, May 16). AI and Compute. OpenAI. https://openai.com/research/ai-and-compute/
Appenzeller, G., Bornstein, M., & Casado, M. (2023, April 27). Navigating the high cost of AI compute. Andreessen Horowitz. https://a16z.com/2023/04/27/navigating-the-high-cost-of-ai-compute/
Apple Inc. (2021, October 18). Introducing M1 Pro and M1 Max: the most powerful chips Apple has ever built. Apple Newsroom. https://www.apple.com/newsroom/2021/10/introducing-m1-pro-and-m1-max-the-most-powerful-chips-apple-has-ever-built/
Apple Inc. (2022, June). Apple unveils M2, taking the breakthrough performance and capabilities of M1 even further. Apple Newsroom. https://www.apple.com/newsroom/2022/06/apple-unveils-m2-with-breakthrough-performance-and-capabilities/
Apple Inc. (2022, March). Apple unveils M1 Ultra, the world’s most powerful chip for a personal computer. Apple Newsroom. https://www.apple.com/newsroom/2022/03/apple-unveils-m1-ultra-the-worlds-most-powerful-chip-for-a-personal-computer/
Apple Inc. (2023, June). Apple introduces M2 Ultra. Apple Newsroom. https://www.apple.com/newsroom/2023/06/apple-introduces-m2-ultra/
ARK Investment Management LLC. (2023, January 31). Big Ideas 2023. https://research.ark-invest.com/hubfs/1_Download_Files_ARK-Invest/Big_Ideas/ARK%20Invest_013123_Presentation_Big%20Ideas%202023_Final.pdf
Bastian, M. (2022, September 8). Training cost for Stable Diffusion was just $600,000 and that is a good sign for AI progress. The Decoder. https://the-decoder.com/training-cost-for-stable-diffusion-was-just-600000-and-that-is-a-good-sign-for-ai-progress/#:~:text=This%20required%20about%20150%2C000%20hours,than%20those%20of%20Stable%20Diffusion.
Barry, D. J. (2023, April 17). Beyond Moore’s Law: New solutions for beating the data growth curve. Microcontroller Tips. https://www.microcontrollertips.com/beyond-moores-law-new-solutions-beating-data-growth-curve/
Bunting, J. (2023, March 14). AI Benchmarks Are Broken. SemiEngineering. https://semiengineering.com/ai-benchmarks-are-broken/
Burt, J. (2022, August 23). Untether AI pulls the curtain rope for its next-gen inferencing system. The Next Platform. https://www.nextplatform.com/2022/08/23/untether-ai-pulls-the-curtain-rope-for-its-next-gen-inferencing-system/
Business Wire. (2021, August 24). Cerebras Systems Announces World’s First Brain-Scale Artificial Intelligence Solution. https://www.businesswire.com/news/home/20210824005644/en/Cerebras-Systems-Announces-World%E2%80%99s-First-Brain-Scale-Artificial-Intelligence-Solution
Business Wire. (2022, June 9). Cadence Cerebrus AI-Based Solution Delivers Transformative Results on Next-Generation Customer Designs. https://www.businesswire.com/news/home/20220609005365/en/Cadence-Cerebrus-AI-Based-Solution-Delivers-Transformative-Results-on-Next-Generation-Customer-Designs
Butler, G. (2022, October 5). SambaNova announces new DataScale SN30 HPC system. DatacenterDynamics. https://www.datacenterdynamics.com/en/news/sambanova-announces-new-datascale-sn30-hpc-system/
Butler, S. (1863). Darwin Among the Machines. In The Notebooks of Samuel Butler.
Cherney, M. A. (2023, June 6). Andrew Ng says AI poses no extinction risk. Silicon Valley Business Journal. https://www.bizjournals.com/sanjose/news/2023/06/06/andrew-ng-says-ai-poses-no-extinction-risk.html
Cottier, B. (2023). Trends in the dollar training cost of machine learning systems. Epoch AI. https://epochai.org/blog/trends-in-the-dollar-training-cost-of-machine-learning-systems
Cuenca, P. (2023, January 25). The Infrastructure Behind Serving DALL-E Mini. Weights & Biases. https://wandb.ai/dalle-mini/dalle-mini/reports/The-Infrastructure-Behind-Serving-DALL-E-Mini–VmlldzoyMTI4ODAy
Dilmengani, C. (2023, June 17). AI chip makers: Top 10 companies in 2023. https://research.aimultiple.com/ai-chip-makers/
Doherty, S. (2021, August 25). Designing the Colossus MK2 IPU: Simon Knowles at Hot Chips 2021. Graphcore. https://www.graphcore.ai/posts/designing-the-colossus-mk2-ipu-simon-knowles-at-hot-chips-2021
Eadline, D. (2023, July 13). The great GPU squeeze is upon us. HPC Wire. https://www.hpcwire.com/2023/07/13/the-great-gpu-squeeze-is-upon-us/
E2Analyst. (2023). GPT-4: Everything you want to know about OpenAI’s new AI model. Medium. https://medium.com/predict/gpt-4-everything-you-want-to-know-about-openais-new-ai-model-a5977b42e495
Edwards, B. (2023, May 24). The lightning onset of AI—what suddenly changed? An Ars Frontiers 2023 recap. Ars Technica. https://arstechnica.com/information-technology/2023/05/the-lightning-onset-of-ai-what-suddenly-changed-an-ars-frontiers-2023-recap/
Edwards, B. (2023, June 8). Nvidia’s new AI superchip combines CPU and GPU to train monster AI systems. Ars Technica. https://arstechnica.com/information-technology/2023/06/nvidias-new-ai-superchip-combines-cpu-and-gpu-to-train-monster-ai-systems/
Freund, K. (2021, August 9). Using AI to help design chips has become a thing. Forbes. https://www.forbes.com/sites/karlfreund/2021/08/09/using-ai-to-help-design-chips-has-become-a-thing/?sh=29e752cb5d9d
Freund, K. (2023, June 13). Cadence AI can increase chip designer productivity by over 10x. Forbes. https://www.forbes.com/sites/karlfreund/2023/06/13/cadence-ai-can-increase-chip-designer-productivity-by-over-10x/?sh=4d885f535f4f
Fu, J. (2022, September 29). AI frontiers in 2022. Better Programming. https://betterprogramming.pub/ai-frontiers-in-2022-5bd072fd13c
Gairola, A. (2023, May 25). Former Google CEO echoes Musk and Hinton’s dire warnings on AI becoming existential risk. Benzinga. https://www.benzinga.com/news/23/05/32566930/former-google-ceo-echoes-musk-and-hintons-dire-warnings-on-ai-becoming-existential-risk
Garanhel, M. (2022, October 14). Top 20 AI Chips of Your Choice in 2022. AI Accelerator Institute. https://www.aiacceleratorinstitute.com/top-20-chips-choice-2022/
Goldie, A., & Mirhoseini, A. (2020, April 3). Chip Design with Deep Reinforcement Learning. Google AI Blog. https://ai.googleblog.com/2020/04/chip-design-with-deep-reinforcement.html
Greenberg, M. (2023, June 6). The best AI features Apple announced at WWDC 2023. VentureBeat. https://venturebeat.com/ai/the-best-ai-features-apple-announced-at-wwdc-2023/
Gupta, A. (2022, March 22). Nvidia’s Grace CPU: The ins and outs of an AI-focused processor. Ars Technica. https://arstechnica.com/gadgets/2022/03/nvidias-grace-cpu-the-ins-and-outs-of-an-ai-focused-processor/
Gwennap, L. (n.d.). Untether Boqueria Targets AI Lead. TechInsights. https://www.techinsights.com/blog/untether-boqueria-targets-ai-lead
Hall, J. (2022, November 21). Cerebras unveils Andromeda AI supercomputer. ExtremeTech. https://www.extremetech.com/extreme/340899-cerebras-unveils-andromeda-ai-supercomputer
Hamblen, M. (2023, February 16). ChatGPT runs 10K Nvidia training GPUs with potential for thousands more. Fierce Electronics. Retrieved from https://www.fierceelectronics.com/sensors/chatgpt-runs-10k-nvidia-training-gpus-potential-thousands-more
Higginbotham, S. (2022, February 14). Google is using AI to design chips for its AI hardware. Protocol. https://www.protocol.com/google-is-using-ai-to-design-chips
Hoffman, K. (2020, February 24). We’re not prepared for the end of Moore’s law. MIT Technology Review. Retrieved from https://www.technologyreview.com/2020/02/24/905789/were-not-prepared-for-the-end-of-moores-law/
Hruska, J. (2021, June 8). Intel’s 2021-2022 roadmap: Alder Lake, Meteor Lake, and a big bet on EUV. ExtremeTech. https://www.extremetech.com/computing/323126-intels-2021-2022-roadmap-alder-lake-meteor-lake-and-a-big-bet-on-euv
Jotrin Electronics. (2022, January 4). A brief history of the development of AI chips. Retrieved from https://www.jotrin.com/technology/details/a-brief-history-of-the-development-of-ai-chips
Jouppi, N., & Patterson, D. (2022, June 29). TPU v4 enables performance, energy, and CO2e efficiency gains. Google Cloud Blog. Retrieved from https://cloud.google.com/blog/topics/systems/tpu-v4-enables-performance-energy-and-co2e-efficiency-gains
Kandel, A. (2023, April 7). Secrets of ChatGPT’s AI Training: A Look at the High-Tech Hardware Behind It. Retrieved from https://www.linkedin.com/pulse/secrets-chatgpts-ai-training-look-high-tech-hardware-behind-kandel/
Kaur, D. (2021, November 3). Here’s what the 2021 global chip shortage is all about. Tech Wire Asia. https://techwireasia.com/2021/11/heres-what-the-2021-global-chip-shortage-is-all-about/
Kennedy, P. (2021, August 24). SambaNova SN10 RDU at Hot Chips 33. ServeTheHome. https://www.servethehome.com/sambanova-sn10-rdu-at-hot-chips-33/
Kennedy, P. (2023, June 17). Nvidia Notches a Modest Grace Superchip Win at ISC 2023. ServeTheHome. Retrieved from https://www.servethehome.com/nvidia-notches-a-modest-grace-superchip-win-at-isc-2023-arm-hpe/
Khare, Y. (2023, June 16). Meta Reveals AI Chips to Revolutionize Computing. Analytics Vidhya. Retrieved from https://finance.yahoo.com/news/1-amd-says-meta-using-174023713.html https://www.analyticsvidhya.com/blog/2023/05/meta-reveals-ai-chips-to-revolutionize-computing/
Lambert, F. (2022, October 1). Tesla Dojo supercomputer ‘tripped power grid’. Electrek. https://electrek.co/2022/10/01/tesla-dojo-supercomputer-tripped-power-grid/
Lee, J., & Nellis, S. (2023, March 9). Groq adapts Meta’s chatbot to its own chips in race against Nvidia. Reuters. https://www.reuters.com/technology/groq-adapts-metas-chatbot-its-own-chips-race-against-nvidia-2023-03-09/
Liu, M. (2022). Get the Latest from re:Invent 2022. AWS re:Post. https://repost.aws/articles/ARWg0vtgR7RriapTABCkBnng/get-the-latest-from-re-invent-2022
McKenzie, J. (2023, June 20). Moore’s law: further progress will push hard on the boundaries of physics and economics. Physics World. https://physicsworld.com/a/moores-law-further-progress-will-push-hard-on-the-boundaries-of-physics-and-economics/
Mitchell, R. (2021, June 19). Mythic announces latest AI chip M1076. Electropages. https://www.electropages.com/blog/2021/06/mythic-announces-latest-ai-chip-m1076
Mirhoseini, A., Goldie, A., Yazgan, M. et al. (2021). Chip placement with deep reinforcement learning. Nature 595, 230–236. https://www.nature.com/articles/s41586-021-03544-w
MLCommons. (2023, March 8). History. MLCommons. Retrieved from https://mlcommons.org/en/history/
Mohan, R. (2023, June 17). AI chip race heats up as AMD introduces rival to Nvidia technology. Tech Xplore. Retrieved from https://techxplore.com/news/2023-06-ai-chip-amd-rival-nvidia.html
Moore, G. E. (1965). Cramming more components onto integrated circuits. Electronics, 38(8), 114-117.
Moore, S. (2022). MLPerf Rankings 2022. IEEE Spectrum. https://spectrum.ieee.org/mlperf-rankings-2022
Morgan, T. P. (2022, October 20). IBM’s AI Accelerator: This Had Better Not Be Just A Science Project. The Next Platform. https://www.nextplatform.com/2022/10/20/ibms-ai-accelerator-this-had-better-not-be-just-a-science-project/
Naik, A. R. (2021, August 4). Explained: Nvidia’s record-setting performance on MLPerf v1.0 training benchmarks. Analytics India Magazine. https://analyticsindiamag.com/explained-nvidias-record-setting-performance-on-mlperf-v1-0-training-benchmarks/
Nikita, S. (2022, May 27). AWS announces general availability of Graviton 3 processors. MGT Commerce. https://www.mgt-commerce.com/blog/aws-announces-general-availability-of-graviton-3-processors/
Narasimhan, S. (2022, June 29). Nvidia partners sweep all categories in MLPerf AI benchmarks. The Official Nvidia Blog. https://blogs.nvidia.com/blog/2022/06/29/nvidia-partners-ai-mlperf/
Narendran, S. (2023, May 11). Every major AI feature announced at Google I/O 2023. ZDNet. Retrieved from https://www.zdnet.com/article/every-major-ai-feature-announced-at-google-io-2023/
Naval Group. (2023, March 2). AI-powered chip design: A revolution in the semiconductor industry. Naval Group Press Room. https://www.naval-group.com/en/news/ai-powered-chip-design-a-revolution-in-the-semiconductor-industry/
Nosta, J. (2023, March 10). Stacked exponential growth: AI is outpacing Moore’s law and evolutionary biology. Medium. https://johnnosta.medium.com/stacked-exponential-growth-ai-is-outpacing-moores-law-and-evolutionary-biology-12882c38b68d
Nvidia. (2021, April 12). Nvidia Announces CPU for Giant AI and High Performance Computing Workloads. Nvidia Newsroom. https://nvidianews.nvidia.com/news/nvidia-announces-cpu-for-giant-ai-and-high-performance-computing-workloads
Nvidia. (2023, May 2). Introducing Nvidia Grace: A CPU specifically designed for giant-scale AI and HPC. Nvidia Newsroom. https://nvidianews.nvidia.com/news/introducing-nvidia-grace-a-cpu-specifically-designed-for-giant-scale-ai-and-hpc
Patel, D., & Ahmad, A. (2023, February 9). The inference cost of search disruption. SemiAnalysis. https://www.semianalysis.com/p/the-inference-cost-of-search-disruption
Peckham, O. (2022, July 7). IBM, Tokyo Electron Announce 3D Chip Stacking Breakthrough. HPCwire. https://www.hpcwire.com/2022/07/07/ibm-tokyo-electron-announce-3d-chip-stacking-breakthrough/
Peckham, O. (2022, September 14). SambaNova Launches Second-Gen DataScale System. HPCwire. https://www.hpcwire.com/2022/09/14/sambanova-launches-second-gen-datascale-system/
Porter, J. (2023, May 24). Microsoft Build 2023: All of the news and announcements. The Verge.https://www.theverge.com/23732609/microsoft-build-2023-news-announcements-ai
PR Newswire. (2018). Synopsys Unveils Fusion Compiler Enabling 20 Percent Higher Quality-of-Results and 2x Faster Time-to-Results. https://www.prnewswire.com/news-releases/synopsys-unveils-fusion-compiler-enabling-20-percent-higher-quality-of-results-and-2x-faster-time-to-results-300744510.html
Precedence Research. (2022). Artificial Intelligence (AI) in Hardware Market. https://www.precedenceresearch.com/artificial-intelligence-in-hardware-market
Ray, T. (2023, May 18). Meta unveils first custom artificial intelligence chip. ZDNet. https://www.zdnet.com/article/meta-unveils-first-custom-artificial-intelligence-chip/
Ray, T. (2023, June 13). AMD unveils MI300X AI chip as generative AI accelerator. ZDNet. https://www.zdnet.com/article/amd-unveils-mi300x-ai-chip-as-generative-ai-accelerator/
Roach, J. (2023, June 17). Intel thinks your next CPU needs an AI processor — here’s why. Digital Trends. https://www.digitaltrends.com/computing/intel-meteor-lake-vpu-computex-2023/
Roy, R., Raiman, J., & Godil, S. (2023, April 5). Designing arithmetic circuits with deep reinforcement learning. Nvidia Developer Blog. Retrieved from https://developer.nvidia.com/blog/designing-arithmetic-circuits-with-deep-reinforcement-learning/
Salvator, D. (2022, April 6). Nvidia Orin Leaps Ahead in Edge AI, Boosting Leadership in MLPerf Tests. The Official Nvidia Blog. https://blogs.nvidia.com/blog/2022/04/06/mlperf-edge-ai-inference-orin/
Salvator, D. (2023, April 5). Inference MLPerf AI. The Official Nvidia Blog. https://blogs.nvidia.com/blog/2023/04/05/inference-mlperf-ai/
Shah, A. (2023, May 31). Google’s Next TPU Looms Large as Company Wagers Future on AI. EnterpriseAI. https://www.enterpriseai.news/2023/05/31/googles-next-tpu-looms-large-as-company-wagers-future-on-ai/
Sharma, S. (2021, December 20). 2021 Was a Breakthrough Year for AI. VentureBeat. https://venturebeat.com/ai/2021-was-a-breakthrough-year-for-ai/
Smith, L. (2023, January 10). 4th Gen Intel Xeon Scalable Processors Launched. StorageReview. https://www.storagereview.com/news/4th-gen-intel-xeon-scalable-processors-launched
Sweeney, T. [@TimSweeneyEpic]. (2023, April 13). Artificial intelligence is doubling at a rate much faster than Moore’s Law’s 2 years, or evolutionary biology’s 2M years. Why? Because we’re bootstrapping it on the back of both laws. And if it can feed back into its own acceleration, that’s a stacked exponential. Twitter. https://twitter.com/TimSweeneyEpic/status/1646645582583267328
Synopsys. (2023). DSO.ai. Retrieved June 2023, from https://www.synopsys.com/ai/chip-design/dso-ai.html
Takahashi, D. (2021, July 22). AI’s got talent: Meet the new rising star in media and entertainment. VentureBeat. https://venturebeat.com/ais-got-talent-meet-the-new-rising-star-in-media-and-entertainment/
Tardi, C. (2023, June 17). Moore’s Law. Investopedia. https://www.investopedia.com/terms/m/mooreslaw.asp
Trader, T. (2021, May 27). NERSC debuts Perlmutter, world’s fastest AI supercomputer. HPC Wire. https://www.hpcwire.com/2021/05/27/nersc-debuts-perlmutter-worlds-fastest-ai-supercomputer/
Turing, A. M. (1950). Computing machinery and intelligence. Mind, 59(236), 433-460. doi:10.1093/mind/LIX.236.433
University of California - San Diego. (2022, August 17). A new neuromorphic chip for AI on the edge, at a small fraction of the energy and size of today’s compute platforms. ScienceDaily. https://www.sciencedaily.com/releases/2022/08/220817114253.htm
Vanian, J., & Leswing, K. (2023, March 13). ChatGPT and generative AI are booming, but at a very expensive price. CNBC. Updated 2023, April 17. https://www.cnbc.com/2023/03/13/chatgpt-and-generative-ai-are-booming-but-at-a-very-expensive-price.html
Vellante, D., & Floyer, D. (2021, April 10). New era of innovation: Moore’s law is not dead and AI is ready to explode. SiliconANGLE. https://siliconangle.com/2021/04/10/new-era-innovation-moores-law-not-dead-ai-ready-explode/
Vincent, J. (2021, June 10). Google is using machine learning to design its next generation of machine learning chips. The Verge. https://www.theverge.com/2021/6/10/22527476/google-machine-learning-chip-design-tpu-floorplanning
Walton, J. (2023, May 18). Nvidia Ada Lovelace and GeForce RTX 40 Series: Everything We Know. Tom’s Hardware. https://www.tomshardware.com/features/nvidia-ada-lovelace-and-geforce-rtx-40-series-everything-we-know
Ward-Foxton, S. (2023, February 10). AI-Powered Chip Design Goes Mainstream. EE Times. https://www.eetimes.com/ai-powered-chip-design-goes-mainstream/
Westfall, R. (2021, November 18). Groq Turbocharges COVID Drug Discovery at Argonne National Laboratory. Futurum Research. https://futurumresearch.com/research-notes/groq-turbocharges-covid-drug-discovery-at-argonne-national-laboratory/
Wiggers, K. (2020, April 7). Tenstorrent reveals Grayskull, an all-in-one system that accelerates AI model training. VentureBeat. https://venturebeat.com/ai/tenstorrent-reveals-grayskull-an-all-in-one-system-that-accelerates-ai-model-training/
Zuhair, M. (2023, July 4). Inflection AI Develops Supercomputer Equipped With 22,000 NVIDIA H100 AI GPUs. Wccftech. https://wccftech.com/inflection-ai-develops-supercomputer-equipped-with-22000-nvidia-h100-ai-gpus/
Acknowledgements
I would like to thank the SuperDataScience Podcast, host Jon Krohn, and guest Ron Diamant in episode 691: A.I. Accelerators: Hardware Specialized for Deep Learning. This episode provided me with valuable insights into the topic of AI hardware. I listened to this podcast while I was researching my essay, and it helped me to understand the different types of AI hardware and how they are developed.
Generative AI models developed by OpenAI (ChatGPT) and Google (Bard) were utilized while writing this essay. Their specific contributions were as follows:
-
Narrative: In the early stages of writing, these models were used to generate ideas for the structure of the essay. In the later stages, they were used as references to employ proper style guidelines.
-
Research: The Bing integration feature of ChatGPT was leveraged throughout the information gathering process to check for additional sources outside of the ones found using traditional search methods.
-
Validation: My written summaries of article contents were checked against the original source to ensure accuracy and avoid plagiarism.