Is it just me or does AI performance seem to be skyrocketing in the last two years?
In case you don’t have this on the top of your mind all the time, Moore’s Law is an observation and projection of a historical trend in the computer hardware manufacturing industry that the number of transistors on integrated circuits doubles approximately every two years. The law is named after Gordon E. Moore, co-founder of Intel Corporation, who described the trend in his 1965 paper.
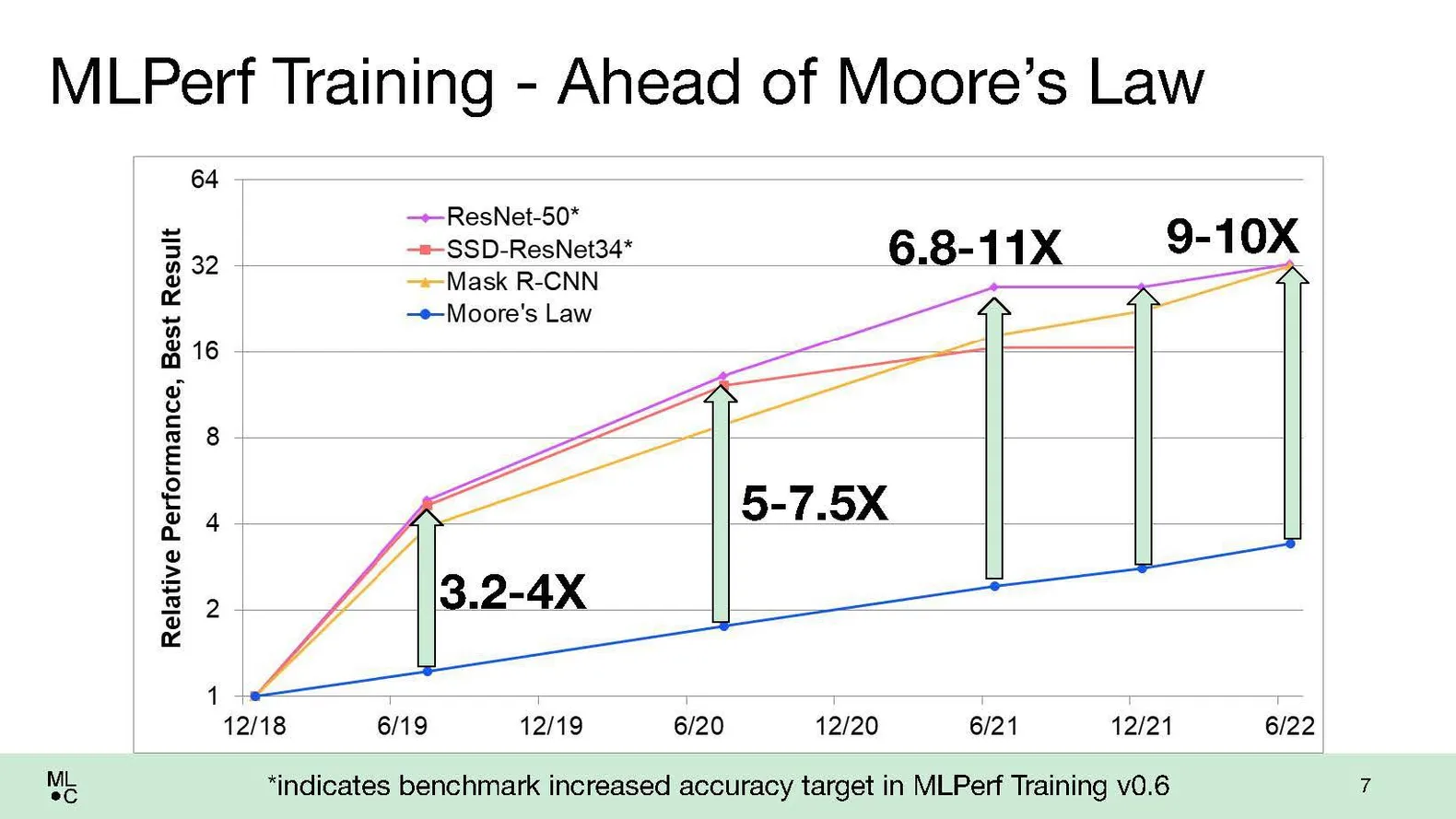
AI Is Outperforming Moore’s Law
According to an article in IEEE Spectrum in June 2022, the MLPerf benchmark showed a two-fold decrease in the training time required for a neural network over the 2021 benchmark. This is much faster than the pace predicted by Moore’s law. The results as of last June are shown below:
Moore’s Law: Not a Direct Predictor of AI Progress
Moore’s Law is primarily focused on the physical aspect of computing hardware, specifically the number of transistors on integrated circuits, rather than actual computing power or computational performance. While it has often been used as a rule of thumb for anticipating increases in computing performance, it doesn’t provide a direct measure or prediction of future capabilities in complex computational tasks such as those benchmarked by MLPerf. As of now, there’s no equivalent ‘law’ or widely accepted predictive model for the performance trajectory of machine learning systems.
It’s worth noting that the correlation between transistor count (which Moore’s Law describes) and performance is not direct, especially for tasks as complex as machine learning. Many other factors, including software algorithms, data I/O speeds, memory hierarchy design, power efficiency, and more, play significant roles in determining the real-world performance of machine learning systems.
Moore’s Law has been a useful guideline for hardware development, but predicting the pace of improvement in machine learning performance is much more complex due to these many additional factors. This is one reason why benchmarks like MLPerf are so valuable - they offer a more holistic view of system performance for machine learning tasks.
What is MLPerf?
MLPerf consists of eight benchmark tests: image recognition, medical-imaging segmentation, two versions of object detection, speech recognition, natural-language processing, recommendation, and a form of gameplay called reinforcement learning. It was founded in 2018 by ML Commons and is often referred to as “the Olympics of machine learning” because computers and software from 21 different companies compete on any or all the tests. This incentivizes hardware companies like Nvidia to put their best foot forward.
Case Study: NVIDIA
To try and wrap your head around how quickly things are moving in the hardware and software optimizations across the ML landscape, lets look at the latest hardware performance from Nvidia.
When the IEEE article came out last June, the A100 was the hardware used for Nvidia’s MLPerf tests and these were the results from MLPerf v2.0.
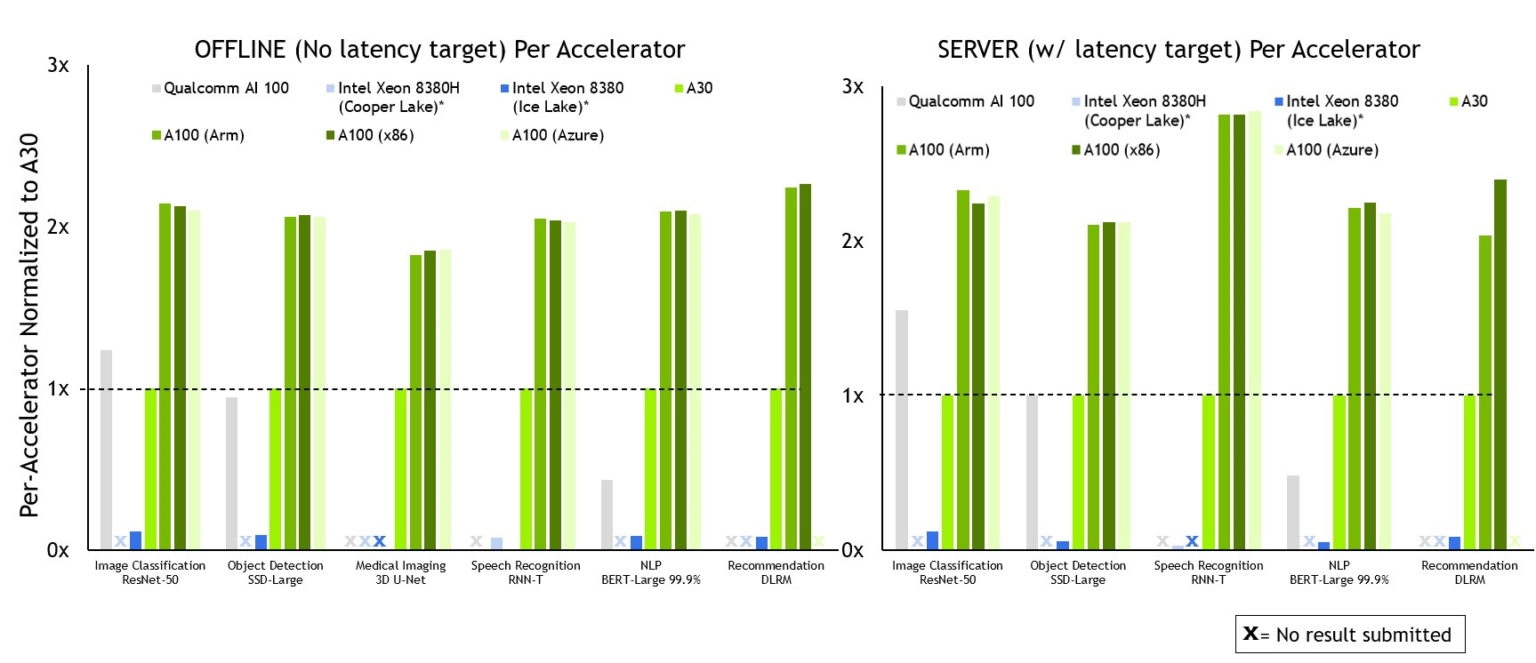
In September of 2022, the H100 was introduced and compared to the A100 in the most recent MLPerf v3.0 in April 2023. The A100 and H100 were compared for the different tasks.
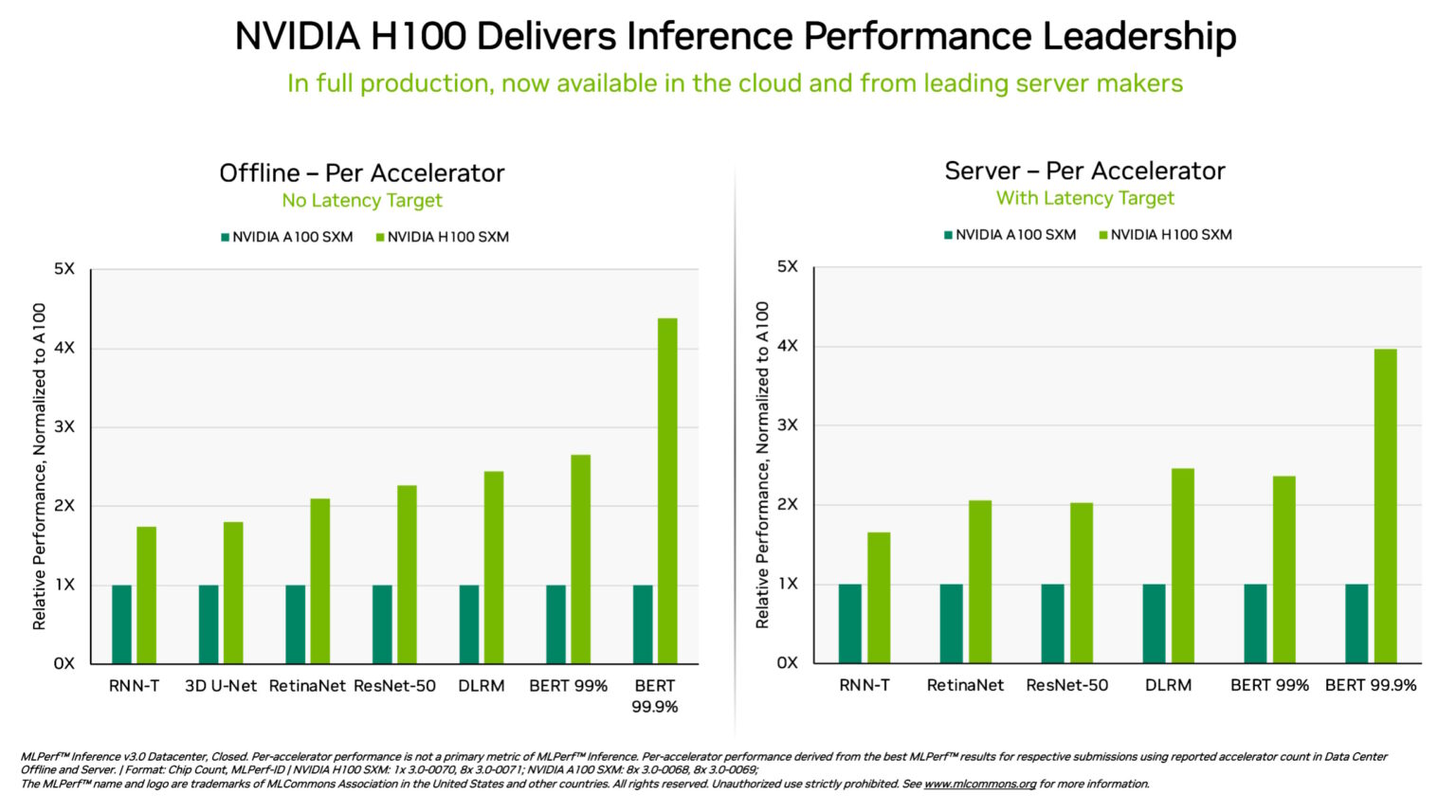
The H100s are making the A100s (that were amazing last year) look like the old Intel chips. Even comparing the most up-to-date H100s to their first iteration, they have shown a 54% performance gain since their debut due to software optimizations. This is incredibly quicker than what is predicted by Moore’s Law.
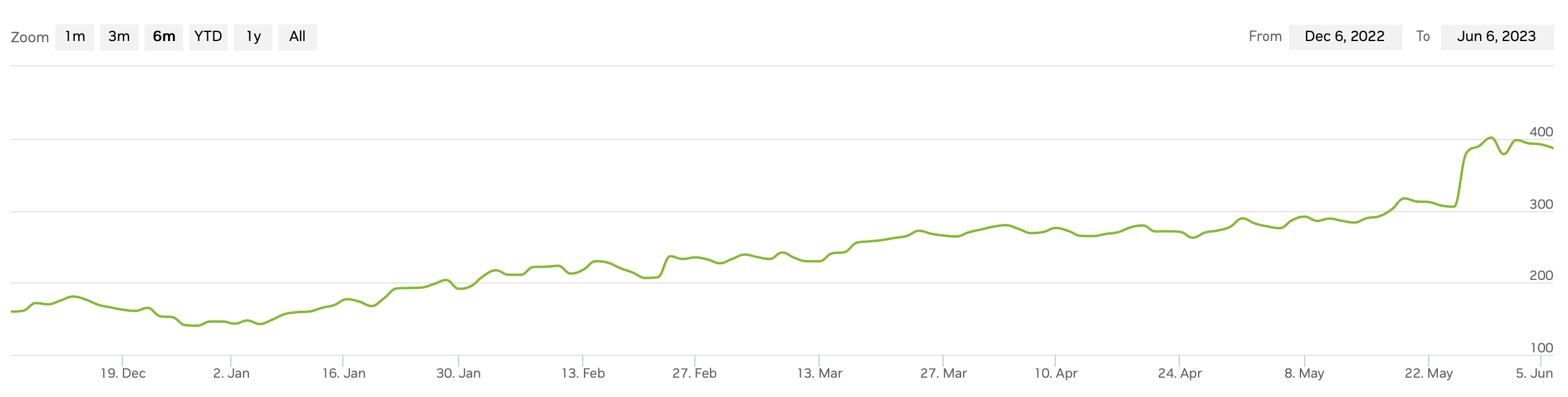
I think I’m starting to further understand Nvidia’s recent stock performance, also clearly outpacing Moore’s Law in recent weeks despite following it pretty consistently in the past, interestingly enough.